在多标签分类设置中,
sklearn.metrics.accuracy_score仅计算子集准确率(3):即对于一个样本,预测的标签集必须与y_true中相应的标签集完全匹配。这种计算准确率的方式有时被称为精确匹配比率(1)。
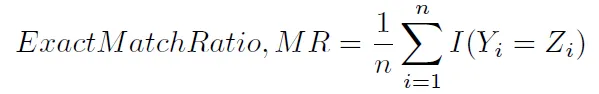
有没有办法在scikit-learn中获得另一种典型的计算准确度的方法,即
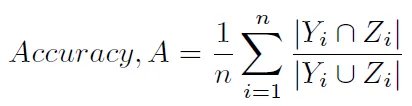
(1) Sorower, Mohammad S. "多标签学习算法的文献综述。" 俄勒冈州立大学,科瓦利斯(2010)。
(2) Tsoumakas,Grigorios和Ioannis Katakis。 "多标签分类:概述。" 希腊塞萨洛尼基亚里士多德大学信息学系(2006)。
(3) Ghamrawi,Nadia和Andrew McCallum。 "集体多标签分类。" 第14届ACM国际信息与知识管理会议论文集。 ACM,2005年。
(4) Godbole, Shantanu和Sunita Sarawagi。 "多标签分类的判别方法。" 《知识发现和数据挖掘进展》。Springer Berlin Heidelberg,2004年。22-30页。