我不理解IDA*如何节省内存空间。
根据我的理解,IDA*是使用迭代加深的A*算法。
A*与IDA*在内存使用量上有什么区别。
难道IDA*的最后一次迭代行为不会像A*那样并且使用相同数量的内存吗?当我追踪IDA*时,我意识到它还必须记住所有低于f(n)阈值的节点的优先级队列。
我了解ID-深度优先搜索如何帮助深度优先搜索,使其能够进行类似广度优先的搜索而不必记住每个节点。但我认为A*已经像深度优先那样行为,即沿途忽略某些子树。迭代加深如何使其使用更少的内存?
另一个问题是,迭代加深的深度优先搜索允许您通过使其行为类似广度优先来找到最短路径。但是,A*已经返回最优最短路径了(假设启发式函数是可接受的)。迭代加深如何帮助它呢?我觉得IDA*的最后一次迭代与A*完全相同。
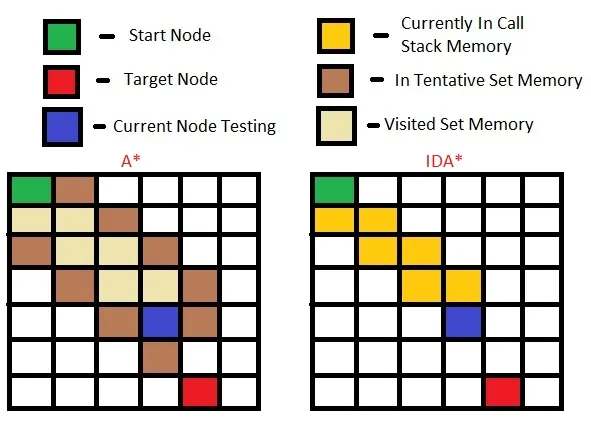

IDA*访问的每个节点都已经包含了它相邻节点的引用,因此当你在调用堆栈中有这个节点(上图中的黄色节点)时,你可以迭代它们。 - Tamir Vered