我有一个数据框,我想做的是在同一位置上列出获胜和失败队伍的得分。我尝试使用lambda函数,但没有成功。我当前拥有的数据框是第一个,我想创建一个形式为第二个问题的数据集。谢谢。
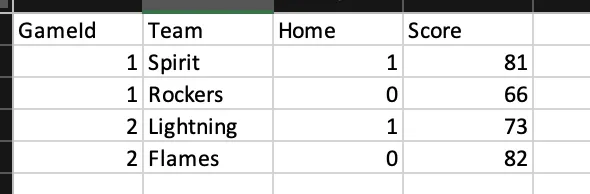

GameId Team Home Score
1 Spirit 1 81
1 Rockers 0 66
2 Lightning 1 73
2 Flames 0 82
Game ID Home Team Away Team Home Score Away Score
1 Spirit Rockers 81 66
2 Lightning Flames 73 82

.map只需44ms。1.maps = {0:'Away',1:'Home'}2.raw_df.Home = raw_df.Home.map(maps)。两种方式都足够快。我个人认为.map看起来更清晰,特别是对于更多的映射。不管怎样,非常好的答案+10。 - Trenton McKinney