我有一个简单的随机森林分类器示例代码,使用了2个决策树对鸢尾花数据集进行分类。最好在jupyter笔记本中运行此代码。
# Setup
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
import numpy as np
# Set seed for reproducibility
np.random.seed(1015)
# Load the iris data
iris = load_iris()
# Create the train-test datasets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target)
np.random.seed(1039)
# Just fit a simple random forest classifier with 2 decision trees
rf = RandomForestClassifier(n_estimators = 2)
rf.fit(X = X_train, y = y_train)
# Define a function to draw the decision trees in IPython
# Adapted from: http://scikit-learn.org/stable/modules/tree.html
from IPython.display import display, Image
import pydotplus
# Now plot the trees individually
for dtree in rf.estimators_:
dot_data = tree.export_graphviz(dtree
, out_file = None
, filled = True
, rounded = True
, special_characters = True)
graph = pydotplus.graph_from_dot_data(dot_data)
img = Image(graph.create_png())
display(img)
draw_tree(inp_tree = dtree)
#print(dtree.tree_.feature)
第一个树的输出为:
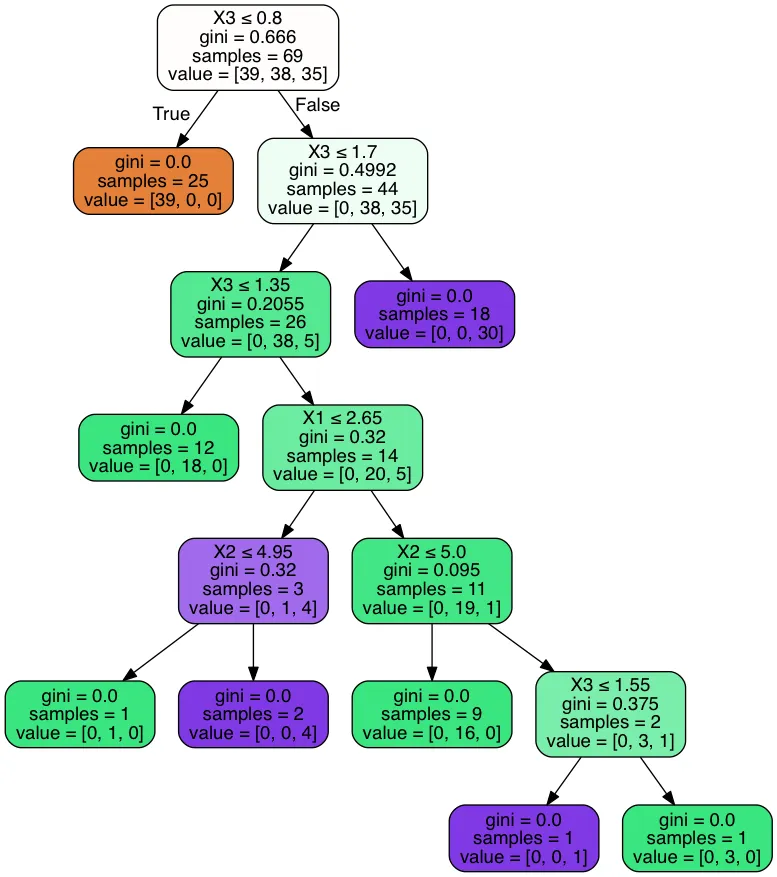
可以观察到第一个决策树有8个叶节点,第二个决策树(未显示)有6个叶节点
如何提取一个简单的numpy数组,其中包含每个决策树和树中每个叶节点的信息:
- 该叶节点的分类结果(例如,预测的最频繁类)
- 所有用于到达该叶节点的决策路径中的特征(布尔值)?
在上面的例子中,我们将拥有:
- 2棵树 -
{0, 1} - 对于树
{0},我们有8个叶节点,索引为{0, 1, ..., 7} - 对于树
{1},我们有6个叶节点,索引为{0, 1, ..., 5} - 对于每棵树中的每个叶节点,我们都有一个单一最频繁预测类,例如在鸢尾花数据集中为
{0, 1, 2} - 对于每个叶节点,我们都有一组布尔值,用于表示构建该树时使用的4个特征。如果在通向叶节点的决策路径中使用了4个特征之一一次或多次,我们就将其视为
True,否则如果它从未在通向叶节点的决策路径中使用,则为False。
请协助将此numpy数组调整为上述代码(循环)。
谢谢
{kind=link}
tree类中的代码了吗?特别是我认为从export_graphiz函数开始的代码是一个很好的起点。https://github.com/scikit-learn/scikit-learn/blob/14031f6/sklearn/tree/export.py#L70 - piman314