如何生成类似于俄亥俄州城镇和城市分布的1000个随机点?很抱歉,我无法精确地定义“像城市一样分布”的概念;均匀分布的中心+小高斯云很容易但是是临时解决方案。
补充:必须有一个2D分布族,其聚类参数可以变化以匹配给定的点集吗?
补充:必须有一个2D分布族,其聚类参数可以变化以匹配给定的点集吗?
从目标区域的水体特征开始建立模型(如果是虚构的地方,可以自己创造一个),然后将靠近河流交汇处、湖岸线和湖河交汇处的城市聚集在一起。接着,建立连接这些主要城市的虚构高速公路。然后,在这些高速公路上合理间隔地添加一些中等规模的城市,最好是靠近高速公路的交汇处。最后,在空旷的地方散布一些小城镇。
new Random().nextGaussian()来实现。由于Java源代码是可用的,您可以查看它:synchronized public double nextGaussian() {
// See Knuth, ACP, Section 3.4.1 Algorithm C.
if (haveNextNextGaussian) {
haveNextNextGaussian = false;
return nextNextGaussian;
} else {
double v1, v2, s;
do {
v1 = 2 * nextDouble() - 1; // between -1 and 1
v2 = 2 * nextDouble() - 1; // between -1 and 1
s = v1 * v1 + v2 * v2;
} while (s >= 1 || s == 0);
double multiplier = StrictMath.sqrt(-2 * StrictMath.log(s)/s);
nextNextGaussian = v2 * multiplier;
haveNextNextGaussian = true;
return v1 * multiplier;
}
}
使用编程绘制30000所房屋
x = r.nextGaussian() * rad/4 + rad;
y = r.nextGaussian() * rad/4 + rad;
产生这个美丽的城市:
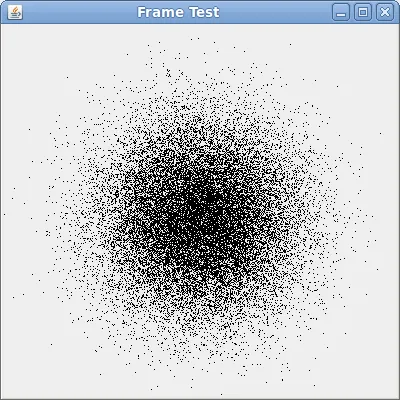
高斯聚类与泊松聚类大小相当有效。
问题:生成大致类似于给定城市(例如美国)的随机点。
子问题:
a)用数字行描述聚类,使得“聚类A类似于聚类B”简化为“clusternumbers(A)类似于clusternumbers(B)”。
通过下面的fcluster运行N = 100和1000个点,并将ncluster = 25,则可得到
N 100 ncluster 25: 22 + 3 r 117
sizes: av 4 10 9 8 7 6 6 5 5 4 4 4 ...
radii: av 117 202 198 140 134 64 62 28 197 144 148 132 ...
N 1000 cluster 25: 22 + 3 r 197
sizes: av 45 144 139 130 85 84 69 63 43 38 33 30 ...
radii: av 197 213 279 118 146 282 154 245 212 243 226 235 ...
b) 找到一组具有2或3个可变参数的随机生成器的组合,以生成不同的聚类。
带有泊松簇大小的高斯聚类可以相当好地匹配城市的聚类:
def randomclusters( N, ncluster=25, radius=1, box=box ):
""" -> N 2d points: Gaussian clusters, Poisson cluster sizes """
pts = []
lam = eval( str( N // ncluster ))
clustersize = lambda: np.random.poisson(lam - 1) + 1
# poisson 2: 14 27 27 18 9 4 %
# poisson 3: 5 15 22 22 17 10 %
while len(pts) < N:
u = uniformrandom2(box)
csize = clustersize()
if csize == 1:
pts.append( u )
else:
pts.extend( inbox( gauss2( u, radius, csize )))
return pts[:N]
# Utility functions --
import scipy.cluster.hierarchy as hier
def fcluster( pts, ncluster, method="average", criterion="maxclust" ):
""" -> (pts, Y pdist, Z linkage, T fcluster, clusterlists)
ncluster = n1 + n2 + ... (including n1 singletons)
av cluster size = len(pts) / ncluster
"""
# Clustering is pretty fast:
# sort pdist, then like Kruskal's MST, O( N^2 ln N )
# Many metrics and parameters are possible; these satisfice.
pts = np.asarray(pts)
Y = scipy.spatial.distance.pdist( pts ) # N*(N-1)/2
Z = hier.linkage( Y, method ) # N-1, like mst
T = hier.fcluster( Z, ncluster, criterion=criterion )
clusters = clusterlists(T)
return (pts, Y, Z, T, clusters)
def clusterlists(T):
""" T = hier.fcluster( Z, t ) e.g. [a b a b c a]
-> [ [0 2 5] [1 3] ] sorted by len, no singletons [4]
"""
clists = [ [] for j in range( max(T) + 1 )]
for j, c in enumerate(T):
clists[c].append( j )
clists.sort( key=len, reverse=True )
n1 = np.searchsorted( map( len, clists )[::-1], 2 )
return clists[:-n1]
def radius( x ):
""" rms |x - xmid| """
return np.sqrt( np.mean( np.var( x, axis=0 )))
# * 100 # 1 degree lat/long ~ 70 .. 111 km