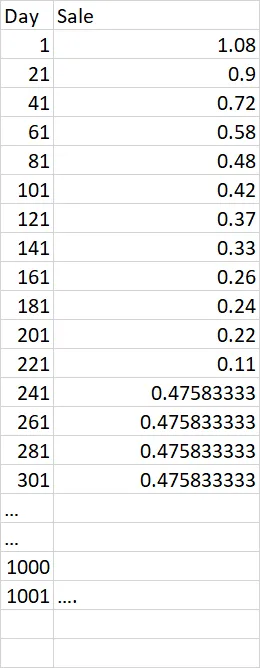
听起来你正在寻找扩展平均值:
import numpy as np
import pandas as pd
df = pd.DataFrame({'day': ['1', '21', '41', '61', '81', '101', '121', '141',
'161', '181', '201', '221'],
'Sale': [1.08, 0.9, 0.72, 0.58, 0.48, 0.42, 0.37, 0.33, 0.26,
0.24, 0.22, 0.11]})
to_add = pd.DataFrame({'day': np.arange(241, 301, 20)})
new_df = pd.concat((df, to_add)).reset_index(drop=True)
new_df['Sale'] = np.where(new_df['Sale'].isna(),
new_df['Sale'].expanding().mean(),
new_df['Sale'])
print(new_df)
day Sale
0 1 1.080000
1 21 0.900000
2 41 0.720000
3 61 0.580000
4 81 0.480000
5 101 0.420000
6 121 0.370000
7 141 0.330000
8 161 0.260000
9 181 0.240000
10 201 0.220000
11 221 0.110000
12 241 0.475833
13 261 0.475833
14 281 0.475833
将 NaN 替换为1,然后取平均值:
import numpy as np
import pandas as pd
df = pd.DataFrame({'day': ['1', '21', '41', '61', '81', '101', '121', '141',
'161', '181', '201', '221'],
'Sale': [1.08, 0.9, 0.72, 0.58, 0.48, 0.42, 0.37, 0.33, 0.26,
0.24, 0.22, 0.11 ]})
to_add = pd.DataFrame({'day': np.arange(241, 301, 20)})
new_df = pd.concat((df, to_add)).reset_index(drop=True)
new_df['Sale'] = np.where(new_df['Sale'].isna(),
new_df['Sale'].fillna(1).shift().expanding().mean(),
new_df['Sale'])
print(new_df)
day Sale
0 1 1.080000
1 21 0.900000
2 41 0.720000
3 61 0.580000
4 81 0.480000
5 101 0.420000
6 121 0.370000
7 141 0.330000
8 161 0.260000
9 181 0.240000
10 201 0.220000
11 221 0.110000
12 241 0.475833
13 261 0.516154
14 281 0.550714