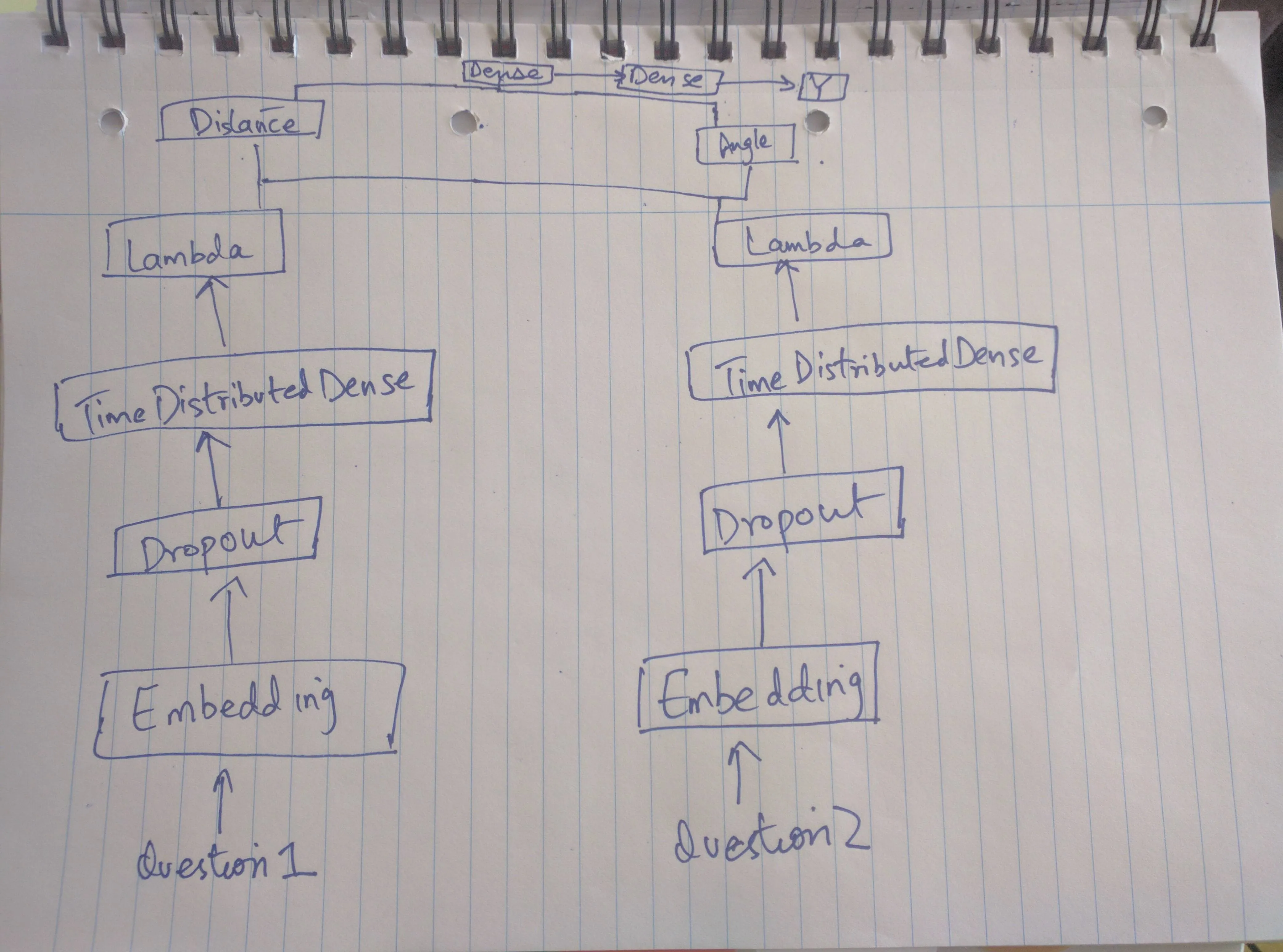
 我正在使用Keras检测问题对之间的相似性。模型结构似乎运行良好,但在model.fit函数上给我报错。我甚至检查了输入数据的数据类型,它是numpy.ndarray。请问有关此事的任何指针,我将不胜感激。
我正在使用Keras检测问题对之间的相似性。模型结构似乎运行良好,但在model.fit函数上给我报错。我甚至检查了输入数据的数据类型,它是numpy.ndarray。请问有关此事的任何指针,我将不胜感激。
ValueError: 检查模型输入时出错:您要传递给模型的Numpy数组列表的大小与模型期望的大小不同。期望看到1个数组,但实际得到以下2个数组的列表: [array([[0, 0, 0, ...,251, 46, 50],[0, 0, 0, ...,7, 40, 6935],[0, 0, 0, ...,17, 314, 2317],... ,[0,...
def Angle(inputs):
length_input_1=K.sqrt(K.sum(tf.pow(inputs[0],2),axis=1,keepdims=True))
length_input_2=K.sqrt(K.sum(tf.pow(inputs[1],2),axis=1,keepdims=True))
result=K.batch_dot(inputs[0],inputs[1],axes=1)/(length_input_1*length_input_2)
angle = tf.acos(result)
return angle
def Distance(inputs):
s = inputs[0] - inputs[1]
output = K.sum(s ** 2,axis=1,keepdims=True)
return output
y=data.is_duplicate.values
tk=text.Tokenizer()
tk.fit_on_texts(list(data.question1.values)+list(data.question2.values))
question1 = tk.texts_to_sequences(data.question1.values)
question1 = sequence.pad_sequences(question1,maxlen=MAX_LEN)
question2 = tk.texts_to_sequences(data.question2.values)
question2 = sequence.pad_sequences(question2,maxlen=MAX_LEN)
word_index = tk.word_index
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
num_features = 300
num_workers = multiprocessing.cpu_count()
context_size = 5
downsampling = 7.5e-06
seed = 1
min_word_count = 5
hs = 1
negative = 5
Quora_word2vec = gensim.models.Word2Vec(
sg=0,
seed=1,
workers=num_workers,
min_count=min_word_count,
size=num_features,
window=context_size, # (2 and 5)
hs=hs, # (1 and 0)
negative=negative, # (5 and 10)
sample=downsampling # (range (0, 1e-5). )
)
Quora_word2vec = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)
embedding_matrix=np.zeros((len(word_index)+1,300))
for word , i in tqdm(word_index.items()): #i is index
try:
embedding_vector = Quora_word2vec[word] #Exception is thrown if there is key error
embedding_matrix[i] = embedding_vector
except Exception as e: #If word is not found continue
continue
--------问题1--------
model1 = Sequential()
print "Build Model"
model1.add(Embedding(
len(word_index)+1,
300,
weights=[embedding_matrix],
input_length=MAX_LEN
))
model1.add(SpatialDropout1D(0.2))
model1.add(TimeDistributed(Dense(300, activation='relu')))
model1.add(Lambda(lambda x: K.sum(x, axis=1), output_shape=(300,)))
print model1.summary()
#---------问题2-------#
model2=Sequential()
model2.add(Embedding(
len(word_index) + 1,
300,
weights=[embedding_matrix],
input_length=MAX_LEN
)) # Embedding layer
model2.add(SpatialDropout1D(0.2))
model2.add(TimeDistributed(Dense(300, activation='relu')))
model2.add(Lambda(lambda x: K.sum(x, axis=1), output_shape=(300,)))
print model2.summary()
#---------Merged------#
#Here you get question embedding
#Calculate distance between vectors
Distance_merged_model=Sequential()
Distance_merged_model.add(Merge(layers=[model1, model2], mode=Distance, output_shape=(1,)))
print Distance_merged_model.summary()
#Calculate Angle between vectors
Angle_merged_model=Sequential()
Angle_merged_model.add(Merge(layers=[model1,model2],mode=Angle,output_shape=(1,)))
print Angle_merged_model.summary()
neural_network = Sequential()
neural_network.add(Dense(2,input_shape=(1,)))
neural_network.add(Dense(1))
neural_network.add(Activation('sigmoid'))
print neural_network.summary()
neural_network.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
checkpoint = ModelCheckpoint('weights.h5', monitor='val_acc', save_best_only=True, verbose=2)
print type(question1)
print type(question2)
neural_network.fit([question1,question2],y=y, batch_size=384, epochs=10,
verbose=1, validation_split=0.3, shuffle=True, callbacks=[checkpoint])
neural_network接受一个形状为(nb_of_examples, 2)的输入,而你提供了两个numpy数组的列表。这是你错误的直接原因。你能否提供更多关于你想要达到的目标的细节?你定义了大量的函数,但最终却尝试拟合可能最简单的网络。 - Marcin Możejko