当我在服务器上运行这个查询时,速度非常慢,而且我不明白为什么会这样。有人可以帮我找出原因吗?
查询语句:
SELECT
"t_dat"."t_year" AS "c0",
"t_dat"."t_month" AS "c1",
"t_dat"."t_week" AS "c2",
"t_dat"."t_day" AS "c3",
"t_purs"."p_id" AS "c4",
sum("t_purs"."days") AS "m0",
sum("t_purs"."timecreated") AS "m1"
FROM "t_dat", "t_purs"
WHERE "t_purs"."created" = "t_dat"."t_key"
AND "t_dat"."t_year" = 2013
AND "t_dat"."t_month" = 3
AND "t_dat"."t_week" = 9
AND "t_dat"."t_day" IN (1,2)
AND "t_purs"."p_id" IN (
'4','15','18','19','20','29',
'31','35','46','56','72','78')
GROUP BY
"t_dat"."t_year",
"t_dat"."t_month",
"t_dat"."t_week",
"t_dat"."t_day",
"t_purs"."p_id"
解释分析:
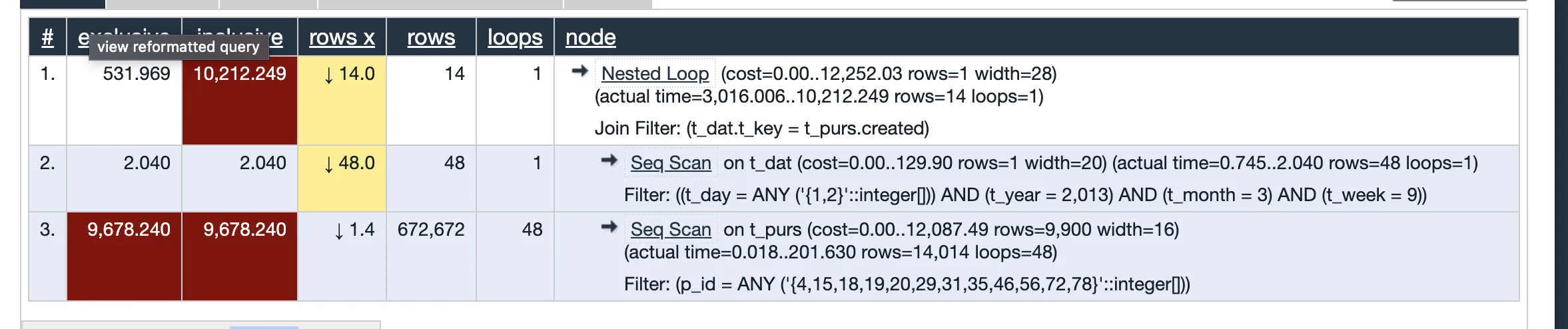
哈希聚合(HashAggregate) (cost=12252.04..12252.04 行=1 宽度=28) (实际时间=10212.374..10212.384 行=10 循环=1)
-> 嵌套循环 (Nested Loop) (cost=0.00..12252.03 行=1 宽度=28) (实际时间=3016.006..10212.249 行=14 循环=1)
合并连接过滤器:(t_dat.t_key = t_purs.created)
-> 序列扫描(Seq Scan)在 t_dat 上 (cost=0.00..129.90 行=1 宽度=20) (实际时间=0.745..2.040 行=48 循环=1)
过滤器:((t_day = ANY ('{1,2}'::integer[])) AND (t_year = 2013) AND (t_month = 3) AND (t_week = 9))
-> 序列扫描(Seq Scan)在 t_purs 上 (cost=0.00..12087.49 行=9900 宽度=16) (实际时间=0.018..201.630 行=14014 循环=48)
过滤器:(p_id = ANY ('{4,15,18,19,20,29,31,35,46,56,72,78}'::integer[]))
总运行时间:10212.470 毫秒