我有一个数据库,其中包含大量的记录(n_building/n_residence表中有数十万条记录,在buildinggeo表中可能有数百万条记录)。这是数据库的简化版本:
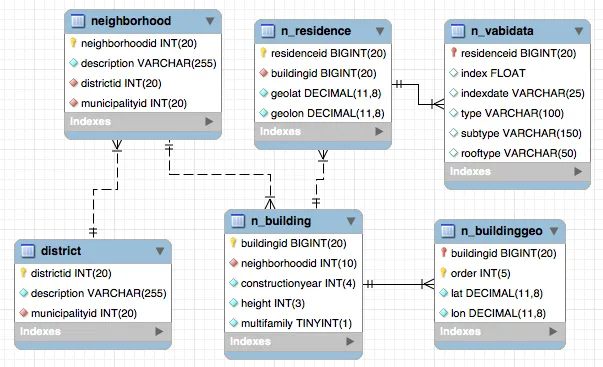
CREATE TABLE IF NOT EXISTS `district` (
`districtid` INT(20) NOT NULL COMMENT 'cbs_wijk_cd',
`description` VARCHAR(255) NOT NULL COMMENT 'cbs_wijk_oms',
`municipalityid` INT(20) NOT NULL COMMENT 'FK gemeente',
PRIMARY KEY (`districtid`),
INDEX `wijk_gemeente_fk` (`municipalityid` ASC),
CONSTRAINT `fk_district_municipality`
FOREIGN KEY (`municipalityid`)
REFERENCES `municipality` (`municipalityid`)
ON DELETE CASCADE
ON UPDATE CASCADE)
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `neighborhood` (
`neighborhoodid` INT(20) NOT NULL COMMENT 'cbs_buurt_cd',
`description` VARCHAR(255) NOT NULL COMMENT 'cbs_buurt_oms',
`districtid` INT(20) NOT NULL COMMENT 'FK wijk',
`municipalityid` INT(20) NOT NULL COMMENT 'FK gemeente',
PRIMARY KEY (`neighborhoodid`),
INDEX `buurt_gemeente_fk` (`municipalityid` ASC),
INDEX `buurt_wijk_fk` (`districtid` ASC),
FULLTEXT INDEX `index_neighborhood_description` (`description` ASC),
CONSTRAINT `fk_neighborhood_municipality`
FOREIGN KEY (`municipalityid`)
REFERENCES `municipality` (`municipalityid`)
ON DELETE CASCADE
ON UPDATE CASCADE,
CONSTRAINT `fk_neighborhood_district`
FOREIGN KEY (`districtid`)
REFERENCES `district` (`districtid`)
ON DELETE CASCADE
ON UPDATE CASCADE)
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `n_building` (
`buildingid` BIGINT(20) NOT NULL,
`neighborhoodid` INT(10) NOT NULL,
`constructionyear` INT(4) NOT NULL,
`height` INT(3) NOT NULL DEFAULT 9,
`multifamily` TINYINT(1) NOT NULL DEFAULT 0,
PRIMARY KEY (`buildingid`),
INDEX `fk_building_buurt_idx` (`neighborhoodid` ASC),
INDEX `index_neighborhoodid_buildingid` (`neighborhoodid` ASC, `buildingid` ASC),
CONSTRAINT `fk_building_neighborhood`
FOREIGN KEY (`neighborhoodid`)
REFERENCES `neighborhood` (`neighborhoodid`)
ON DELETE CASCADE
ON UPDATE CASCADE)
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `n_buildinggeo` (
`buildingid` BIGINT(20) NOT NULL,
`order` INT(5) NOT NULL,
`lat` DECIMAL(11,8) NOT NULL,
`lon` DECIMAL(11,8) NOT NULL,
PRIMARY KEY (`buildingid`, `order`),
CONSTRAINT `fk_buildinggeo_building`
FOREIGN KEY (`buildingid`)
REFERENCES `n_building` (`buildingid`)
ON DELETE CASCADE
ON UPDATE CASCADE)
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `n_residence` (
`residenceid` BIGINT(20) NOT NULL,
`buildingid` BIGINT(20) NOT NULL,
`geolat` DECIMAL(11,8) NOT NULL,
`geolon` DECIMAL(11,8) NOT NULL,
PRIMARY KEY (`residenceid`),
INDEX `fk_residence_building_idx` (`buildingid` ASC),
INDEX `index_geoloat_geolon_residenceid` (`geolat` ASC, `geolon` ASC, `residenceid` ASC),
INDEX `index_geolat` (`geolat` ASC),
INDEX `index_geolon` (`geolon` ASC),
CONSTRAINT `fk_residence_building`
FOREIGN KEY (`buildingid`)
REFERENCES `n_building` (`buildingid`)
ON DELETE CASCADE
ON UPDATE CASCADE)
ENGINE = InnoDB;
CREATE TABLE IF NOT EXISTS `n_vabidata` (
`residenceid` BIGINT(20) NOT NULL,
`index` FLOAT NULL COMMENT ' ',
`indexdate` VARCHAR(25) NULL,
`type` VARCHAR(100) NULL,
`subtype` VARCHAR(150) NULL,
`rooftype` VARCHAR(50) NULL,
PRIMARY KEY (`residenceid`),
CONSTRAINT `fk_vabidata_residence`
FOREIGN KEY (`residenceid`)
REFERENCES `n_residence` (`residenceid`)
ON DELETE CASCADE
ON UPDATE CASCADE)
ENGINE = InnoDB;
我的目标是创建一个JSON表示,包含这个数据库中某一部分内容,格式如下(以下是匿名数据):
[
{
"buildingid": "632100000000000",
"buurtid": "6320103",
"constructionyear": "1969",
"height": "9",
"multifamily": "0",
"gemeenteid": "632",
"geo": [
{
"lat": "52.000",
"lon": "4.000"
},
{
"lat": "52.000",
"lon": "4.000"
},
{
"lat": "52.000",
"lon": "4.000"
},
{
"lat": "52.000",
"lon": "4.000"
},
{
"lat": "52.000",
"lon": "4.000"
}
],
"res": [
{
"residenceid": "632010000000000",
"surface": "159",
"postalcode": "3400AA",
"streetname": "Streetname",
"housenumber": "00",
"clusternr": "6320103533",
"owner": "onbekend",
"usageelec": "2463",
"usagegas": "2006",
"nomupd": "0",
"cpwin": "0",
"cpble": "0",
"enet": "0",
"gnet": "0",
"type": null
}
]
}
]
有两种方法可以过滤数据库:通过邻居id(该邻居的所有建筑等)或通过边界框(所有在其中的建筑等)。起初,我决定以非常简单的方式进行:
$path2 = Config::Path(2);//minlat
$path3 = Config::Path(3);//minlon
$path4 = Config::Path(4);//maxlat
$path5 = Config::Path(5);//maxlon
if (($path2 && is_numeric($path2) && $path3 && is_numeric($path3) &&
$path4 && is_numeric($path4) && $path5 && is_numeric($path5)) ||
($path2 == "district" && $path3 && is_numeric($path3))) {
if ($path2 == "neighborhood") {
$buildings = DBUtils::FetchQuery("
SELECT b.`buildingid`, b.`neighborhoodid` AS buurtid, b.`constructionyear`,
b.`height`, b.`multifamily`, n.`municipalityid` AS gemeenteid
FROM `neighborhood` n
INNER JOIN `n_building` b ON b.`neighborhoodid` = n.`neighborhoodid`
INNER JOIN `n_residence` r ON r.`buildingid` = b.`buildingid`
WHERE b.`neighborhoodid` = '$path3'
GROUP BY b.`buildingid`;
");
} else {
$buildings = DBUtils::FetchQuery("
SELECT b.`buildingid`, b.`neighborhoodid` AS buurtid, b.`constructionyear`,
b.`height`, b.`multifamily`, n.`municipalityid` AS gemeenteid
FROM `neighborhood` n
INNER JOIN `n_building` b ON b.`neighborhoodid` = n.`neighborhoodid`
INNER JOIN `n_residence` r ON r.`buildingid` = b.`buildingid`
WHERE r.`geolat` >= '$path2'
AND r.`geolon` >= '$path3'
AND r.`geolat` <= '$path4'
AND r.`geolon` <= '$path5'
GROUP BY b.`buildingid`;
");
}
if ($buildings && count($buildings) > 0) {
for ($i = 0; $i < count($buildings); $i++) {
$building = $buildings[$i];
$buildinggeo = DBUtils::FetchQuery("
SELECT bg.`lat`, bg.`lon`
FROM `n_buildinggeo` bg
WHERE bg.`buildingid` = '$building[buildingid]';
");
if ($buildinggeo && count($buildinggeo) > 0) {
$buildings[$i]['geo'] = $buildinggeo;
$buildingresidences = DBUtils::FetchQuery("
SELECT r.`residenceid`, r.`surface`, r.`postalcode`, r.`streetname`,
r.`housenumber`, r.`clusternr`, r.`owner`, r.`usageelec`,
r.`usagegas`, r.`nomupd`, r.`cpwin`, r.`cpble`, r.`enet`,
r.`gnet`, v.`type`
FROM `n_residence` r
LEFT OUTER JOIN `n_vabidata` v ON r.`residenceid` = v.`residenceid`
WHERE r.`buildingid` = '$building[buildingid]';
");
if ($buildingresidences && count($buildingresidences) > 0) {
$buildings[$i]['res'] = $buildingresidences;
}
}
}
echo json_encode($buildings);
}
}
后来我决定在一个查询中获取所有建筑物/住宅/ Vabidata信息,并从中创建所需的JSON结构,因为每个请求中大部分时间(> 5栋建筑)都花费在获取住宅数据上。
$path2 = Config::Path(2);//minlat
$path3 = Config::Path(3);//minlon
$path4 = Config::Path(4);//maxlat
$path5 = Config::Path(5);//maxlon
if (($path2 && is_numeric($path2) && $path3 && is_numeric($path3) &&
$path4 && is_numeric($path4) && $path5 && is_numeric($path5)) ||
($path2 == "district" && $path3 && is_numeric($path3))) {
if ($path2 == "district") {
$results = DBUtils::FetchQuery("
SELECT b.`buildingid`, b.`neighborhoodid`, b.`constructionyear`,
b.`height`, b.`multifamily`, n.`municipalityid`, r.`residenceid`,
r.`surface`, r.`postalcode`, r.`streetname`, r.`housenumber`,
r.`clusternr`, r.`owner`, r.`usageelec`, r.`usagegas`,
r.`nomupd`, r.`cpwin`, r.`cpble`, r.`enet`, r.`gnet`,
v.`type`
FROM `neighborhood` n
INNER JOIN `n_building` b ON b.`neighborhoodid` = n.`neighborhoodid`
INNER JOIN `n_residence` r ON r.`buildingid` = b.`buildingid`
LEFT OUTER JOIN `n_vabidata` v ON r.`residenceid` = v.`residenceid`
WHERE b.`neighborhoodid` = '$path3';
");
} else {
$results = DBUtils::FetchQuery("
SELECT b.`buildingid`, b.`neighborhoodid`, b.`constructionyear`,
b.`height`, b.`multifamily`, n.`municipalityid`, r.`residenceid`,
r.`surface`, r.`postalcode`, r.`streetname`, r.`housenumber`,
r.`clusternr`, r.`owner`, r.`usageelec`, r.`usagegas`,
r.`nomupd`, r.`cpwin`, r.`cpble`, r.`enet`, r.`gnet`,
v.`type`
FROM `neighborhood` n
INNER JOIN `n_building` b ON b.`neighborhoodid` = n.`neighborhoodid`
INNER JOIN `n_residence` r ON r.`buildingid` = b.`buildingid`
LEFT OUTER JOIN `n_vabidata` v ON r.`residenceid` = v.`residenceid`
WHERE r.`geolat` >= '$path2'
AND r.`geolon` >= '$path3'
AND r.`geolat` <= '$path4'
AND r.`geolon` <= '$path5';
");
}
if ($results && count($results) > 0) {
$buildings = array();
for ($i = 0; $i < count($results); $i++) {
$b = $results[$i];
if (!array_key_exists($b['buildingid'],$buildings)) {
$buildings[$b['buildingid']] = array(
"buildingid" => $b['buildingid'],
"buurtid" => $b['neighborhoodid'],
"constructionyear" => $b['constructionyear'],
"height" => $b['height'],
"multifamily" => $b['multifamily'],
"gemeenteid" => $b['municipalityid'],
"res" => array()
);
}
$buildings[$b['buildingid']]['res'][] = array(
"residenceid" => $b['residenceid'],
"surface" => $b['surface'],
"postalcode" => $b['postalcode'],
"streetname" => $b['streetname'],
"housenumber" => $b['housenumber'],
"clusternr" => $b['clusternr'],
"owner" => $b['owner'],
"usageelec" => $b['usageelec'],
"usagegas" => $b['usagegas'],
"nomupd" => $b['nomupd'],
"cpwin" => $b['cpwin'],
"cpble" => $b['cpble'],
"enet" => $b['enet'],
"gnet" => $b['gnet'],
"type" => $b['type']
);
}
$buildings = array_values($buildings);
for ($i = 0; $i < count($buildings); $i++) {
$building = $buildings[$i];
$buildinggeo = DBUtils::FetchQuery("
SELECT bg.`lat`, bg.`lon`
FROM `n_buildinggeo` bg
WHERE bg.`buildingid` = '$building[buildingid]';
");
if ($buildinggeo && count($buildinggeo) > 0) {
$buildings[$i]['geo'] = $buildinggeo;
}
}
echo json_encode($buildings);
}
}
然而,这种方法似乎比之前的方法慢了30-70%。我的问题是:你们中的任何人能找到原因(可能还有解决方案),为什么这两个查询的性能都如此糟糕?如果您有任何问题或需要任何其他信息,请提出。 编辑 下面是第二个查询(全部合并)边界框版本的EXPLAIN结果:

EXPLAINе‘Ҫд»Ө并жЈҖжҹҘдәҶжҪңеңЁзҡ„зјәеӨұзҙўеј•пјҹиҜ·жіЁж„ҸдёҚиҰҒж”№еҸҳеҺҹж„ҸпјҢжҲ‘дјҡе°ҪеҠӣдҪҝзҝ»иҜ‘йҖҡдҝ—жҳ“жҮӮгҖӮ - Marvin