编辑:我同意Roland的看法,我不需要在Shiny特定的内容上花太多的文字。删除了这些内容,并思考后增加了数据框在应该呈现的样子。
编辑_2:虽然shiny的内容与问题无关,但是我根据Roland的解决方案创建了一个例子,如果路人感兴趣可以查看我所做的内容。请耐心等待图形加载;可能会有点慢。
我正在尝试使用R和shiny绘制一组预测建模数据。我有四个变量,我想显示它们之间的交互作用,以轮廓图的形式展示。对于每个变量,我都要求用户定义一个范围以及一个保持值。每个变量有两种情况:
- 用作轴变量之一:该范围确定了我为该变量在模型中预测新响应值的值。
- 未直接出现在图表中:保持值用于将非特征变量设置为一个常数值,以便我的另外两个变量预测结果仅给出每个
x和y组合的唯一/单个表面z值。
我遇到了处理数据的问题,以便友好地生成一组轮廓图。我理想情况下希望屏幕显示四个变量之间的6个交互作用(4C2)。
我基本上需要两组数据:
- 一个是用于训练模型的输入数据集的原始形式(这样我就可以使用
predict(model, newData)来获得用于z值的输出列) - 原始数据集的子集/重新排列形式,用于绘制/分组
对于友好的分组版本,这是我所需要的内容(在我的想法中;也许有更好的方法):
| x | y | z | col | row |
|----------+----------+---+-----+-----|
| var1_min | var2_min | z | 1 | 1 |
| var1_min | ... | z | 1 | 1 |
| var1_min | var2_max | z | 1 | 1 |
| ... | ... | z | 1 | 1 |
| var1_max | var2_min | z | 1 | 1 |
| var1_max | ... | z | 1 | 1 |
| var1_max | var2_max | z | 1 | 1 |
|----------+----------+---+-----+-----|
| var1_min | var3_min | z | 1 | 2 |
| var1_min | ... | z | 1 | 2 |
| var1_min | var3_max | z | 1 | 2 |
| ... | ... | z | 1 | 2 |
| var1_max | var3_min | z | 1 | 2 |
| var1_max | ... | z | 1 | 2 |
| var1_max | var3_max | z | 1 | 2 |
|----------+----------+---+-----+-----|
| ... | ... | z | | |
|----------+----------+---+-----+-----|
| var3_min | var4_min | z | 3 | 2 |
| var3_min | ... | z | 3 | 2 |
| var3_min | var4_max | z | 3 | 2 |
| ... | ... | z | 3 | 2 |
| var3_max | var4_min | z | 3 | 2 |
| var3_max | ... | z | 3 | 2 |
| var3_max | var4_max | z | 3 | 2 |
|----------+----------+---+-----+-----|
以这种方式,我拥有了我的
x和y值,相应预测响应的列,以及用于创建facet_grid的东西(一个2x3或3x2的facet)。对于预测数据框架,其形式必须与我的初始预测数据相匹配,并且几乎类似于上述形式的转换/宽形式:
| var1 | var2 | var3 | var4 |
|-----------+-----------+-----------+-----------|
| var1_min | var2_min | var3_hold | var4_hold |
| var1_min | ... | var3_hold | var4_hold |
| var1_min | var2_max | var3_hold | var4_hold |
| ... | ... | var3_hold | var4_hold |
| var1_max | var2_min | var3_hold | var4_hold |
| var1_max | ... | var3_hold | var4_hold |
| var1_max | var2_max | var3_hold | var4_hold |
| ... | ... | ... | ... |
| var1_hold | var2_hold | var3_max | var4_min |
| var1_hold | var2_hold | var3_max | ... |
| var1_hold | var2_hold | var3_max | var4_max |
我将这输入模型中,以获取预测响应作为等高线图中的 z 使用。
由于我需要将变量排列成一个公共轴比例尺,跨越面板行或下面板列(可以是任意一个,不需要两个都有),所以情况也变得棘手起来。我会像这样排列组合:
| x | y | row | column |
|------+------+-----+--------|
| var1 | var2 | 1 | 1 |
| var1 | var3 | 2 | 1 |
| var2 | var3 | 1 | 2 |
| var2 | var4 | 2 | 2 |
| var4 | var3 | 1 | 3 |
| var4 | var1 | 2 | 3 |
现在我可以拥有三列和两行的外观,其中第一列具有共享的
var1轴,第二列具有var2,第三列具有var4。我正在考虑手动使用
expand.grid来创建六个变量的唯一组合。完成后,我意识到每一行都会使用其保持值设置了两个变量,所以也许我可以创建这些六个组合的列表,然后将非保持值变量提取到两个新列中以用于绘图数据框?有什么建议吗?
下面是一个恶劣的例子,我尝试着运用三个变量,着重研究
var1和c(var2, var3)之间的交互作用:# the min/max arguments to `seq()` are like the user-defined range
# take the second argument to `c()` is to be user-defined hold value
library(ggplot2)
var1 <- seq(0, 25, length.out = 10) # hold value = 11.1
var2 <- seq(5, 45, length.out = 10) # hold value = 17
var3 <- seq(55, 90, length.out = 10) # hold value = 72
# create combinations between var1 and var2, with var3 held
test_data <- expand.grid(var1 = var1, var2 = var2, var3 = 72)
# same, but for var1 vs. var3, with var2 held
test_data <- rbind(test_data,
expand.grid(var1 = var1, var2 = 17, var3 = var3))
# create response; analog to using predict() in real life
test_data$resp <- (test_data$var1 + test_data$var2) / test_data$var3
# facet variable placeholder and filling in
test_data$facet <- rep("", nrow(test_data))
test_data[test_data$var2 == 17, "facet"] <- "var1 vs. var3"
test_data[test_data$var3 == 72, "facet"] <- "var1 vs. var2"
# now I melted
test_data2 <- melt(test_data, id.vars = c("var1", "resp", "facet"))
不幸的是,这给我留下了一堆情况,其中value被填充了来自var2和var3的所有保留值,因此我必须将它们删除:
test_data2 <- test_data2[test_data2$value != 72 & test_data2$value != 17, ]
现在,我能做到这个:
ggplot(test_data2, aes(x = var1, y = value, z = resp)) +
stat_contour() + facet_grid(~ facet)
已经得到了我想要的数字范围。 现在我猜我需要一种优雅的方式来进行组合并保存值,而不会产生丑陋的结果。
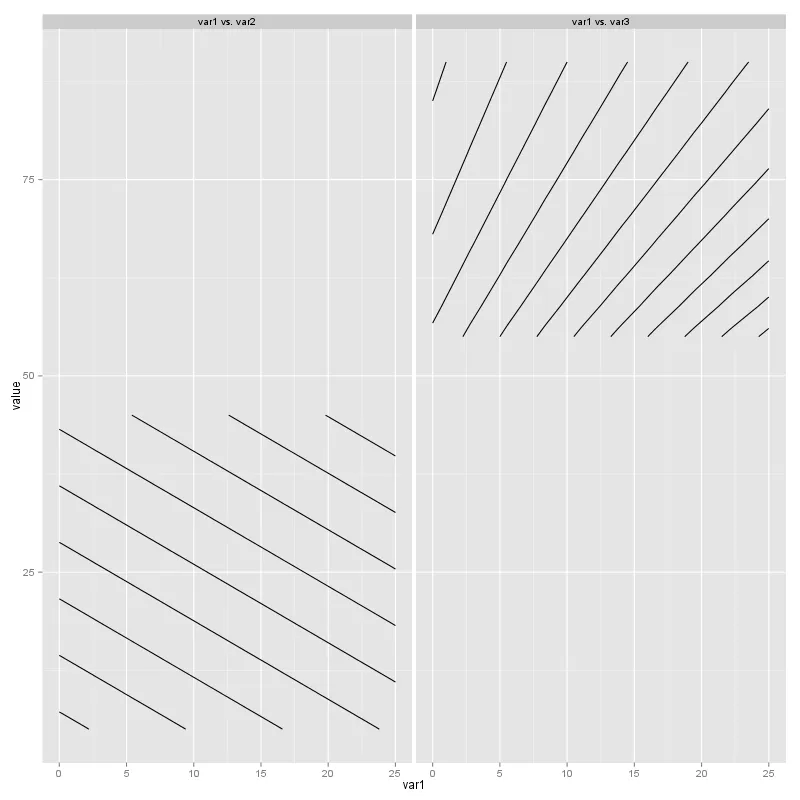
这是一个更新版本,现在我知道如何在同一坐标轴上绘制行/列(因为我有两列和一行,所以需要在两个面板中将y轴设置为相同的变量var1):
ggplot(test_data2, aes(x = value, y = var1, z = resp)) +
stat_contour() + facet_grid(~ facet, scales = "free_x")

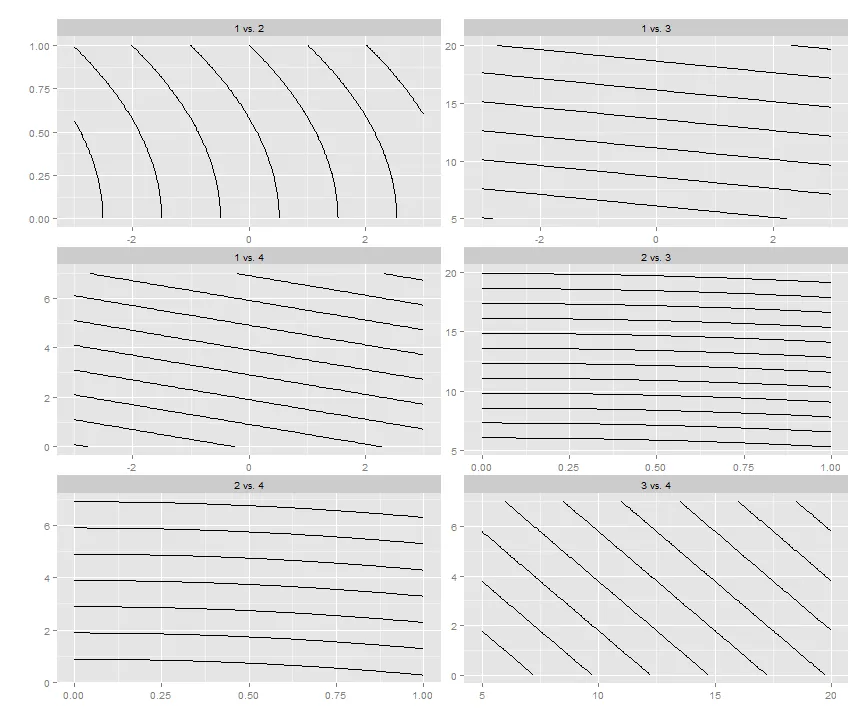
facet_grid的scales参数。 - Rolandscales = "free_y"对于该情况没有任何作用。我需要做的是在同一 y 轴上绘制(使用var1,公共变量),然后使用scales = "free_x"。我添加了那个图。 - Hendyshinyapps.io。已更新! - Hendy