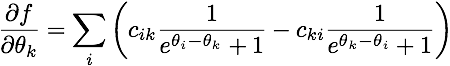我正在尝试使用
这里有一个关于
我不知道为什么它失败了。由于这一行代码,错误信息被显示出来:https://github.com/scipy/scipy/blob/master/scipy/optimize/optimize.py#L853 所以这个“Wolfe线搜索”似乎没有成功,但我不知道如何继续...任何帮助都将不胜感激!
scipy.optimize来最小化以下函数:
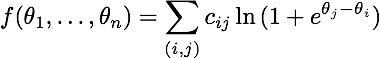
其梯度为:
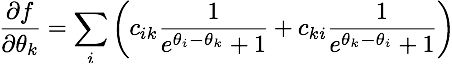
(对于那些感兴趣的人,这是一种布拉德利-特里-卢斯模型的似然函数,与逻辑回归密切相关。)
很明显,将所有参数都加上一个常数不会改变函数的值。因此,我让 \theta_1 = 0。这是在Python中实现目标函数和梯度的方法(其中theta在这里变成了x):
def objective(x):
x = np.insert(x, 0, 0.0)
tiles = np.tile(x, (len(x), 1))
combs = tiles.T - tiles
exps = np.dstack((zeros, combs))
return np.sum(cijs * scipy.misc.logsumexp(exps, axis=2))
def gradient(x):
zeros = np.zeros(cijs.shape)
x = np.insert(x, 0, 0.0)
tiles = np.tile(x, (len(x), 1))
combs = tiles - tiles.T
one = 1.0 / (np.exp(combs) + 1)
two = 1.0 / (np.exp(combs.T) + 1)
mat = (cijs * one) + (cijs.T * two)
grad = np.sum(mat, axis=0)
return grad[1:] # Don't return the first element
这里有一个关于
cijs可能长什么样子的例子:[[ 0 5 1 4 6]
[ 4 0 2 2 0]
[ 6 4 0 9 3]
[ 6 8 3 0 5]
[10 7 11 4 0]]
这是我运行的代码,用于进行最小化:
x0 = numpy.random.random(nb_items - 1)
# Let's try one algorithm...
xopt1 = scipy.optimize.fmin_bfgs(objective, x0, fprime=gradient, disp=True)
# And another one...
xopt2 = scipy.optimize.fmin_cg(objective, x0, fprime=gradient, disp=True)
然而,在第一次迭代中它总是失败:
Warning: Desired error not necessarily achieved due to precision loss.
Current function value: 73.290610
Iterations: 0
Function evaluations: 38
Gradient evaluations: 27
我不知道为什么它失败了。由于这一行代码,错误信息被显示出来:https://github.com/scipy/scipy/blob/master/scipy/optimize/optimize.py#L853 所以这个“Wolfe线搜索”似乎没有成功,但我不知道如何继续...任何帮助都将不胜感激!