总结
在同一个numpy数组中,计算np.cos需要3.2秒,而在Linux Mint上运行np.sin需要548秒(九分钟)。
查看此存储库获取完整代码。
我有一个脉冲信号(见下图),需要调制到高频载波上,模拟激光多普勒测振仪。因此,需要对信号及其时间基准进行重新采样以匹配载波的更高采样率。
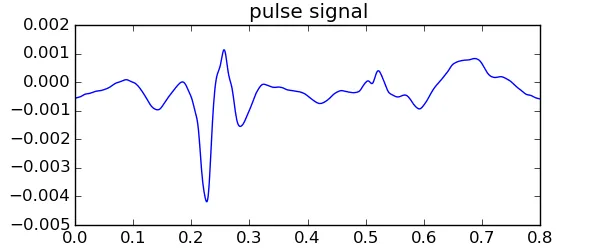
在以下解调过程中,需要用到相位差载波sin(omega * t)和同相载波cos(omega * t)。奇怪的是,计算这些函数的时间高度依赖于计算时间向量的方式。
时间向量t1直接使用np.linspace计算,t2使用在scipy.signal.resample中实现的方法。
pulse = np.load('data/pulse.npy') # 768 samples
pulse_samples = len(pulse)
pulse_samplerate = 960 # 960 Hz
pulse_duration = pulse_samples / pulse_samplerate # here: 0.8 s
pulse_time = np.linspace(0, pulse_duration, pulse_samples,
endpoint=False)
carrier_freq = 40e6 # 40 MHz
carrier_samplerate = 100e6 # 100 MHz
carrier_samples = pulse_duration * carrier_samplerate # 80 million
t1 = np.linspace(0, pulse_duration, carrier_samples)
# method used in scipy.signal.resample
# https://github.com/scipy/scipy/blob/v0.17.0/scipy/signal/signaltools.py#L1754
t2 = np.arange(0, carrier_samples) * (pulse_time[1] - pulse_time[0]) \
* pulse_samples / float(carrier_samples) + pulse_time[0]
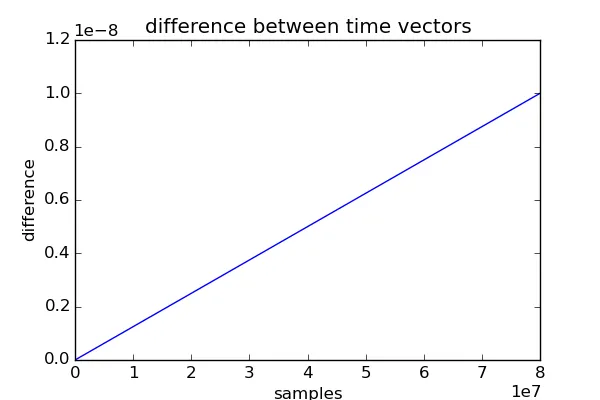
如下图所示,时间向量不完全相同。在8000万个样本时,差异t1-t2达到1e-8。
 在我的电脑上,计算t1的同相和移位载波每个需要3.2秒。然而,使用t2计算移位载波需要540秒,也就是9分钟。这几乎是相同的8000万个值。
在我的电脑上,计算t1的同相和移位载波每个需要3.2秒。然而,使用t2计算移位载波需要540秒,也就是9分钟。这几乎是相同的8000万个值。omega_t1 = 2 * np.pi * carrier_frequency * t1
np.cos(omega_t1) # 3.2 seconds
np.sin(omega_t1) # 3.3 seconds
omega_t2 = 2 * np.pi * carrier_frequency * t2
np.cos(omega_t2) # 3.2 seconds
np.sin(omega_t2) # 9 minutes
我在我的32位笔记本和64位台式机上都可以重现这个错误,两者都运行着 Linux Mint 17。然而,在我室友的MacBook上,“慢正弦”计算所需的时间与其他三个计算一样短。
我在64位AMD处理器上运行Linux Mint 17.03,在32位Intel处理器上运行Linux Mint 17.2。
make test。 - Finwood