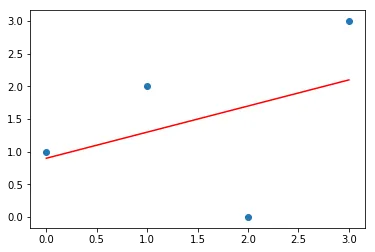
我正在尝试使用梯度下降将一条线拟合到几个点上。我对此不是很精通,但我试图用python将其数学算法写下来。它运行了几次迭代,但我的预测在某个点似乎爆炸了。以下是代码:
import numpy as np
import matplotlib.pyplot as plt
def mean_squared_error(n, A, b, m, c):
e = 0
for i in range(n):
e += (b[i] - (m*A[i] + c)) ** 2
return e/n
def der_wrt_m(n,A,b,m,c):
d = 0
for i in range(n):
d += (2 * (b[i] - (m*A[i] + c)) * (-A[i]))
return d/n
def der_wrt_c(n,A,b,m,c):
d = 0
for i in range(n):
d += (2 * (b[i] - (m*A[i] + c)))
return d/n
def update(n,A,b,m,c,descent_rate):
return descent_rate * der_wrt_m(n,A,b,m,c)), descent_rate * der_wrt_c(n,A,b,m,c))
A = np.array(((0,1),
(1,1),
(2,1),
(3,1)))
x = A.T[0]
b = np.array((1,2,0,3), ndmin=2 ).T
y = b.reshape(4)
def descent(x,y):
m = 0
c = 0
descent_rate = 0.00001
iterations = 100
n = len(x)
plt.scatter(x, y)
u = np.linspace(0,3,100)
prediction = 0
for itr in range(iterations):
print(m,c)
prediction = prediction + m * x + c
m,c = update(n,x,y,m,c,descent_rate)
plt.plot(u, u * m + c, '-')
descent(x,y)
这是我的输出:
0 0
19.25 -10.5
-71335.1953125 24625.9453125
5593771382944640.0 -2166081169939480.2
-2.542705027685638e+48 9.692684648057364e+47
2.40856742196228e+146 -9.202614421953049e+145
-inf inf
nan nan
nan nan
nan nan
nan nan
nan nan
nan nan
etc...
更新:值不再爆炸,但收敛情况仍不理想。
# We could also solve it using gradient descent
import numpy as np
import matplotlib.pyplot as plt
def mean_squared_error(n, A, b, m, c):
e = 0
for i in range(n):
e += ((b[i] - (m * A[i] + c)) ** 2)
#print("mse:",e/n)
return e/n
def der_wrt_m(n,A,b,m,c):
d = 0
for i in range(n):
# d += (2 * (b[i] - (m*A[i] + c)) * (-A[i]))
d += (A[i] * (b[i] - (m*A[i] + c)))
#print("Dm",-2 * d/n)
return (-2 * d/n)
def der_wrt_c(n,A,b,m,c):
d = 0
for i in range(n):
d += (2 * (b[i] - (m*A[i] + c)))
#print("Dc",d/n)
return d/n
def update(n,A,b,m,c, descent_rate):
return (m - descent_rate * der_wrt_m(n,A,b,m,c)),(c - descent_rate * der_wrt_c(n,A,b,m,c))
A = np.array(((0,1),
(1,1),
(2,1),
(3,1)))
x = A.T[0]
b = np.array((1,2,0,3), ndmin=2 ).T
y = b.reshape(4)
def descent(x,y):
m = 0
c = 0
descent_rate = 0.0001
iterations = 10000
n = len(x)
plt.scatter(x, y)
u = np.linspace(0,3,100)
prediction = 0
for itr in range(iterations):
prediction = prediction + m * x + c
m,c = update(n,x,y,m,c,descent_rate)
loss = mean_squared_error(n, A, b, m, c)
print(loss)
print(m,c)
plt.plot(u, u * m + c, '-')
descent(x,y)
经过约10000次迭代,使用学习率为0.0001后,现在的图表如下所示:
[4.10833186 5.21468937]
1.503547594304175 -1.9947003678083184
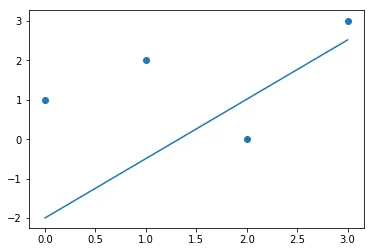
然而,最小二乘拟合显示出以下形状: