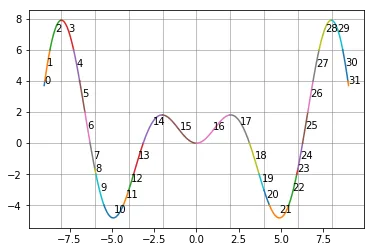
我有轨迹数据,其中每个轨迹由一系列坐标(x,y点)组成,每个轨迹都有一个唯一的ID。
这些轨迹在x-y平面上,我想将整个平面划分为相等大小的网格(正方形网格)。这个网格显然是看不见的,但用于将轨迹划分为子段。每当轨迹与网格线相交时,它就在那里被分割,并成为具有新ID的新子轨迹。
我已经包含了一个简单的手工图表,以清楚说明我的期望。
这些轨迹在x-y平面上,我想将整个平面划分为相等大小的网格(正方形网格)。这个网格显然是看不见的,但用于将轨迹划分为子段。每当轨迹与网格线相交时,它就在那里被分割,并成为具有新ID的新子轨迹。
我已经包含了一个简单的手工图表,以清楚说明我的期望。
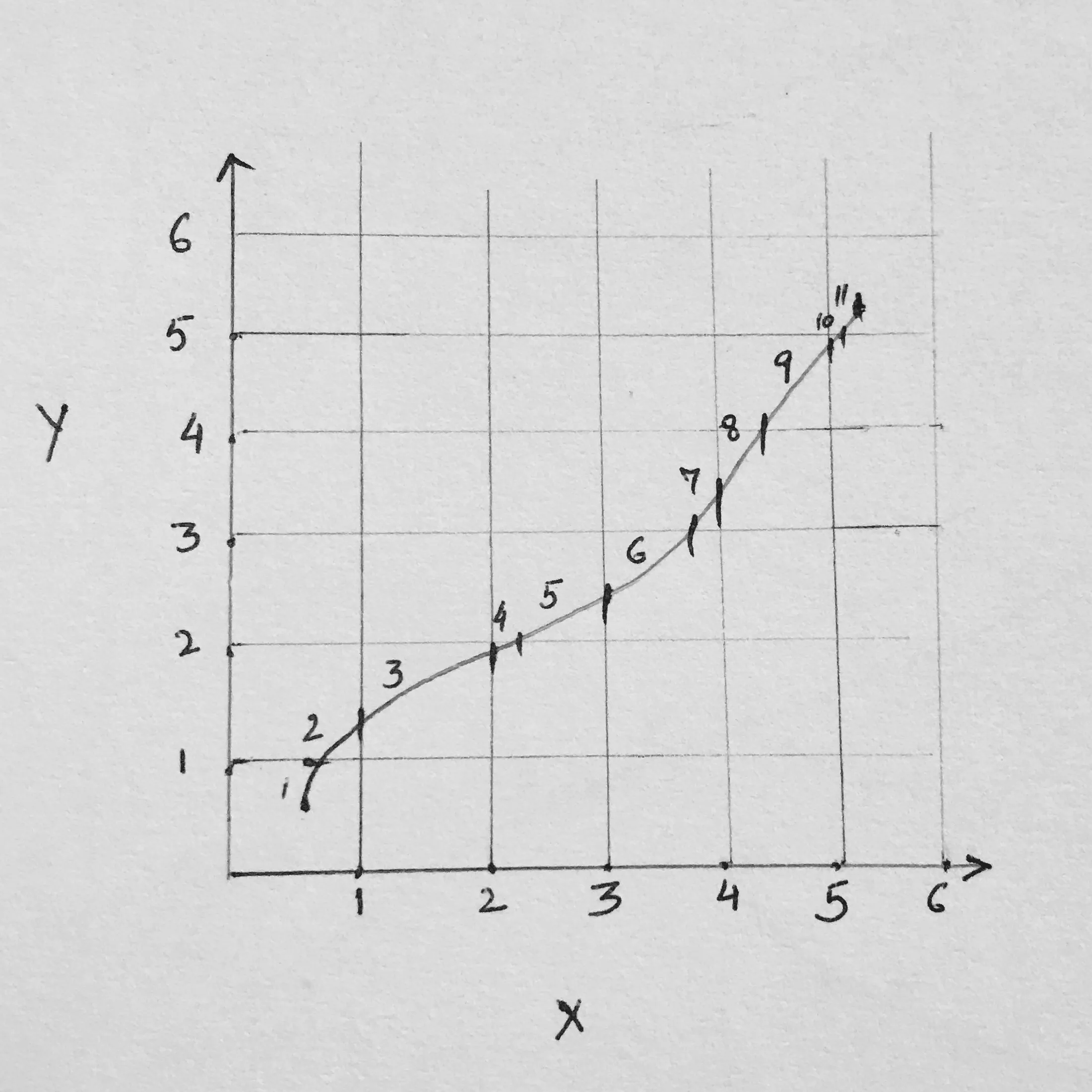
#finding cell id for each coordinate
#cellid = (coord / cellSize).astype(int)
cellid = (coord / 0.5).astype(int)
cellid
Out[] : array([[1, 1],
[3, 1],
[4, 2],
[4, 4],
[5, 5],
[6, 5]])
#Getting x-cell id and y-cell id separately
x_cellid = cellid[:,0]
y_cellid = cellid[:,1]
#finding total number of cells
xmax = df.xcoord.max()
xmin = df.xcoord.min()
ymax = df.ycoord.max()
ymin = df.ycoord.min()
no_of_xcells = math.floor((xmax-xmin)/ 0.5)
no_of_ycells = math.floor((ymax-ymin)/ 0.5)
total_cells = no_of_xcells * no_of_ycells
total_cells
Out[] : 25
由于飞机现在被分成了25个单元格,每个单元格都有一个cellid。为了找到交点,也许我可以检查轨迹中的下一个坐标,如果cellid保持不变,则该轨迹段位于同一单元格中,并且与网格没有交点。例如,如果x_cellid[2]大于x_cellid[0],则该段与垂直网格线相交。尽管如此,我仍然不确定如何找到与网格线相交并将轨迹在交点处分段的方法并给它们新的id。