我使用pandas更新Excel表格时遇到了问题,通过在表格中写入新值来更新。我已经有一个现有的数据框df1,它从MySheet1.xlsx读取值。因此,这需要是一个新数据框,或者以某种方式复制并覆盖现有数据框。
电子表格格式如下:
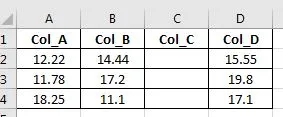
我有一个Python列表:values_list = [12.34, 17.56, 12.45]。我的目标是在Col_C标题下垂直插入列表值。它目前会水平覆盖整个数据框,而不保留当前值。
df2 = pd.DataFrame({'Col_C': values_list})
writer = pd.ExcelWriter('excelfile.xlsx', engine='xlsxwriter')
df2.to_excel(writer, sheet_name='MySheet1')
workbook = writer.book
worksheet = writer.sheets['MySheet1']
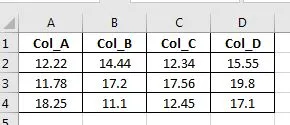


cell = 'C%d'%(index + 2),它将解析为单元格引用 - 即当 index = 0 时,cell ='C2',我认为您不应更改。 您可以将ws [cell] = row [0]更改为ws [cell] = row ['Col_C'],它会起作用。 希望这回答了您的问题。 - patrickjlong1pandas.read_excel()上的usecols参数按名称或位置选择特定列。 - patrickjlong1