我知道文档术语矩阵是描述一组文档中出现频率的术语的数学矩阵。在文档-术语矩阵中,行对应于集合中的文档,列对应于术语。
我正在使用sklearn的CountVectorizer从字符串(文本文件)中提取特征以简化我的任务。以下代码根据sklearn_documentation返回一个文档术语矩阵。
输出如下:
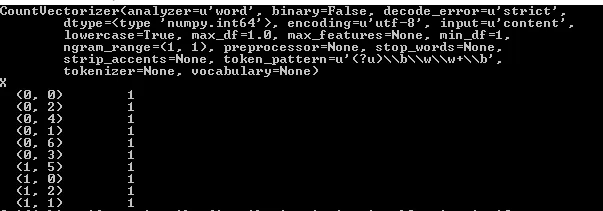
我不明白这个矩阵是如何计算的,请讨论代码中所示的例子。我已经阅读了来自Wikipedia的另一个例子,但是无法理解。
我正在使用sklearn的CountVectorizer从字符串(文本文件)中提取特征以简化我的任务。以下代码根据sklearn_documentation返回一个文档术语矩阵。
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
vectorizer = CountVectorizer(min_df=1)
print(vectorizer)
content = ["how to format my hard disk", "hard disk format problems"]
X = vectorizer.fit_transform(content) #X is Term-document matrix
print(X)
输出如下:
我不明白这个矩阵是如何计算的,请讨论代码中所示的例子。我已经阅读了来自Wikipedia的另一个例子,但是无法理解。