我希望在R中为以下数据拟合等温模型。最简单的等温模型是 Langmuir 模型,可以在此处找到 页面底部给出了该模型。我提供的最小化可工作示例 (MWE) 如下,但会产生错误。不知道是否有适用于等温模型的 R 包。
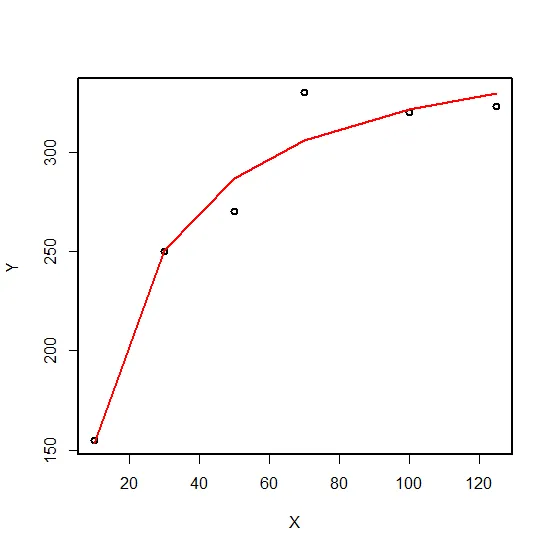
X <- c(10, 30, 50, 70, 100, 125)
Y <- c(155, 250, 270, 330, 320, 323)
Data <- data.frame(X, Y)
LangIMfm2 <- nls(formula = Y ~ Q*b*X/(1+b*X), data = Data, start = list(Q = 1, b = 0.5), algorith = "port")
Error in nls(formula = Y ~ Q * b * X/(1 + b * X), data = Data, start = list(Q = 1, :
Convergence failure: singular convergence (7)
编辑
一些非线性模型可以转化为线性模型。我的理解是,非线性模型的估计值与其线性模型形式之间可能存在一对一的关系,但它们相应的标准误差并不相关。这个说法是否正确?将非线性模型转化为线性模型拟合时有什么注意事项吗?
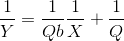
start = list(Q = 300, b = 1)。 - Marat Talipov