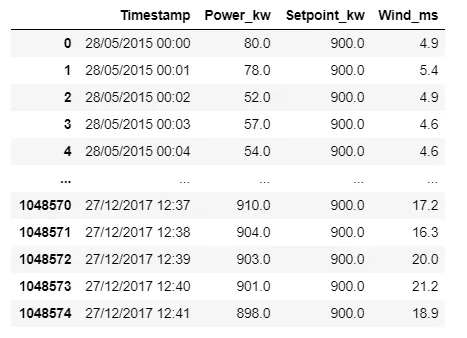
每一分钟都展示着力量,但我想将它们归纳到每30分钟。
Series.resample可以帮助您设置时间戳作为索引; 然后使用series.resample('30T').sum()
您可以在要保留的系列上使用cumsum。
然后仅选择每30个位置的索引(np.arange(0,len(df),30))。
然后向后迭代数据帧并从第n-1行中找到的总和减去第n行以仅保留最后30分钟的值。 迭代效率不高,但由于数据集有100万行,如果您每30行取1行,则应该很快(33,333次迭代)。
df['cumsum'] = df["Power_kw"].cumsum()
df_30_min = df.iloc[np.arange(0, len(df), 30)].copy()
for i in range(len(df_30_min), 1, -1):
df_30_min.iloc[i-1, df_30_min.columns.get_loc('B')] -= df_30_min.iloc[i-2, df_30_min.columns.get_loc('B')]
series.resample('30T').sum()。 - Ferris