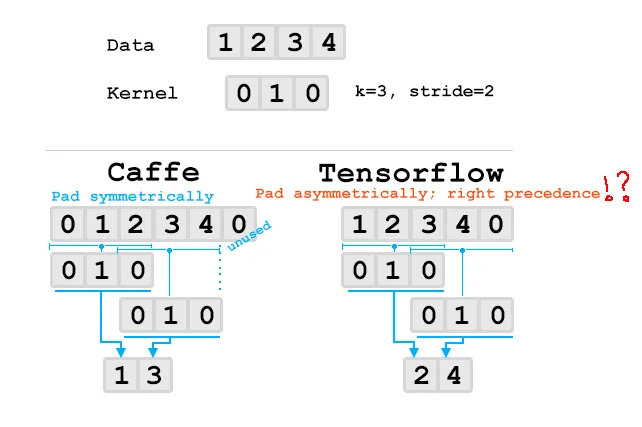
为什么TensorFlow选择优先在底部右侧进行填充?
对我来说,使用“SAME”填充时,从第一个真实像素开始启动卷积核的中心锚点会感觉很合理。由于使用了非对称填充,这导致与其他一些框架存在差异。我确实明白,从原则上讲,非对称填充是好的,因为否则就会留下未使用的填充行/列。
如果TensorFlow将优先考虑左侧和顶部的填充,它将执行与Caffe/cudnn/$frameworks相同的卷积和权重,并且无论填充如何,权重转换都将兼容。
代码:
import numpy as np
import tensorflow as tf
import torch
import torch.nn as nn
tf.enable_eager_execution()
def conv1d_tf(data, kernel_weights, stride):
filters = np.reshape(kernel_weights, [len(kernel_weights), 1, 1])
out = tf.nn.conv1d(
value=data,
filters=filters,
stride=stride,
padding='SAME',
data_format='NCW',
)
return out
def conv1d_pytorch(data, kernel_weights, stride):
filters = np.reshape(kernel_weights, [1, 1, len(kernel_weights)])
kernel_size = len(kernel_weights)
size = data.shape[-1]
def same_padding(size, kernel_size, stride, dilation):
padding = ((size - 1) * (stride - 1) + dilation * (kernel_size - 1)) //2
return padding
padding = same_padding(size=size, kernel_size=kernel_size, stride=stride, dilation=0)
conv = nn.Conv1d(
in_channels=1,
out_channels=1,
kernel_size=kernel_size,
stride=stride,
bias=False,
padding=padding,
)
conv.weight = torch.nn.Parameter(torch.from_numpy(filters))
return conv(torch.from_numpy(data))
data = np.array([[[1, 2, 3, 4]]], dtype=np.float32)
kernel_weights = np.array([0, 1], dtype=np.float32)
stride = 2
out_tf = conv1d_tf(data=data, kernel_weights=kernel_weights, stride=stride)
out_pytorch = conv1d_pytorch(data=data, kernel_weights=kernel_weights, stride=stride)
print('TensorFlow: %s' % out_tf)
print('pyTorch: %s' % out_pytorch)
输出:
TensorFlow: tf.Tensor([[[2. 4.]]], shape=(1, 1, 2), dtype=float32)
pyTorch: tensor([[[1., 3.]]], grad_fn=<SqueezeBackward1>)