我看到这个问题被多次提出,但其他问题的解决方案都没有起作用!
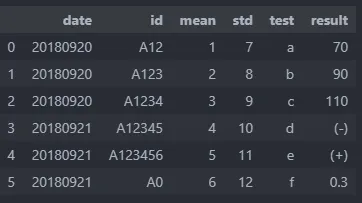
我有一个数据框架,如下所示:
df = pd.DataFrame({
"date": ["20180920"] * 3 + ["20180921"] * 3,
"id": ["A12","A123","A1234","A12345","A123456","A0"],
"mean": [1,2,3,4,5,6],
"std" :[7,8,9,10,11,12],
"test": ["a", "b", "c", "d", "e", "f"],
"result": [70, 90, 110, "(-)", "(+)", 0.3],})
使用 pivot_table
df_sum_table = (pd.pivot_table(df,index=['id'], columns = ['date'], values = ['mean','std']))
我得到
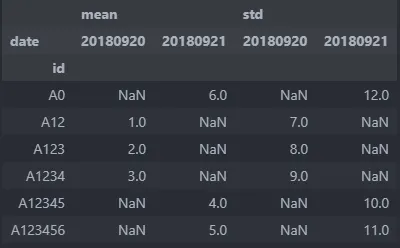
df_sum_table.columns
MultiIndex([('mean', '20180920'),
('mean', '20180921'),
( 'std', '20180920'),
( 'std', '20180921')],
names=[None, 'date'])
所以我想把
date列下移一行并删除id行,但保留其中的id名称,可以参考如下过去的解决方案:
尝试在DataFrame.pivot中创建多重索引时出现ValueError
从使用pivot_table()创建的df中删除索引名称
在pandas中进行pivot_table后重置为平坦索引
保留pandas pivot_table中的索引
df_sum_table = (pd.pivot_table(df,index=['id'], columns = ['date'], values = ['mean','std'])).reset_index().rename_axis(None, axis=1)
但是遇到了错误
类型错误:必须像
names一样传递列表。
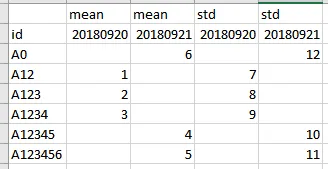
如何删除date但在第一列中保留id?
期望输出结果
@jezrael
.rename_axis(columns={'date': None}).fillna('').reset_index().T.reset_index(level=1).T.reset_index(drop=True).reset_index(drop=True)- Alexander