我希望指定日期的格式,因为它是欧洲格式(否则,将其作为索引列后,日期将不会按顺序排列)。我按照以下教程操作:
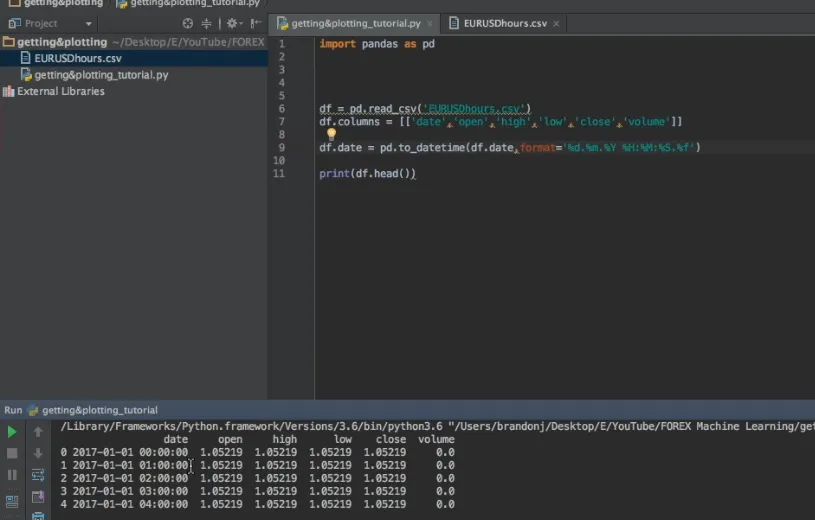
但是在我执行后:
df.date=pd.to_datetime(df.date,format='%d.%m.%Y %H:%M:%S.%f')
我收到了这个错误。
df = pd.read_csv("F:\Python\Jupyter notes\AUDCAD1h.csv")
df.columns = [['date', 'open','high','low','close','volume']]
df.head()
Out[66]:
date open high low close volume
0 01.01.2015 00:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
1 01.01.2015 01:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
2 01.01.2015 02:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
3 01.01.2015 03:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
4 01.01.2015 04:00:00.000 GMT-0500 0.94821 0.94821 0.94821 0.94821 0.0
df.Date=pd.to_datetime(df.date,format='%d.%m.%Y %H:%M:%S.%f')
Traceback (most recent call last):
File "<ipython-input-67-29b50fd32986>", line 1, in <module>
df.Date=pd.to_datetime(df.date,format='%d.%m.%Y %H:%M:%S.%f')
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 376, in to_datetime
result = _assemble_from_unit_mappings(arg, errors=errors)
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 446, in _assemble_from_unit_mappings
unit = {k: f(k) for k in arg.keys()}
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 446, in <dictcomp>
unit = {k: f(k) for k in arg.keys()}
File "C:\Users\AM\Anaconda3\lib\site-packages\pandas\core\tools\datetimes.py", line 441, in f
if value.lower() in _unit_map:
AttributeError: 'tuple' object has no attribute 'lower'
为什么我按照别人的代码却出现了错误?我已经完全复制了代码,这是怎么回事?谢谢。
pd.to_datetime(df['date'], dayfirst=True)- SamuelNLP