我正在尝试进行投资组合优化,以返回最大化我的效用函数的权重。我可以很好地完成这部分工作,包括约束权重总和为1并且权重还给我一个目标风险。我还为[0 <= 权重 <= 1]设置了边界。这段代码如下:
def rebalance(PortValue, port_rets, risk_tgt):
#convert continuously compounded returns to simple returns
Rt = np.exp(port_rets) - 1
covar = Rt.cov()
def fitness(W):
port_Rt = np.dot(Rt, W)
port_rt = np.log(1 + port_Rt)
q95 = Series(port_rt).quantile(.05)
cVaR = (port_rt[port_rt < q95] * sqrt(20)).mean() * PortValue
mean_cVaR = (PortValue * (port_rt.mean() * 20)) / cVaR
return -1 * mean_cVaR
def solve_weights(W):
import scipy.optimize as opt
b_ = [(0.0, 1.0) for i in Rt.columns]
c_ = ({'type':'eq', 'fun': lambda W: sum(W) - 1},
{'type':'eq', 'fun': lambda W: sqrt(np.dot(W, np.dot(covar, W))\
* 252) - risk_tgt})
optimized = opt.minimize(fitness, W, method='SLSQP', constraints=c_, bounds=b_)
if not optimized.success:
raise BaseException(optimized.message)
return optimized.x # Return optimized weights
init_weights = Rt.ix[1].copy()
init_weights.ix[:] = np.ones(len(Rt.columns)) / len(Rt.columns)
return solve_weights(init_weights)
现在我可以深入研究这个问题了。我将我的权重存储在一个MultIndex pandas Series中,以便每个资产都是对应于某个资产类别的ETF。当等权重组合被打印出来时,它看起来像这样:
equity CZA 0.045455 IWM 0.045455 SPY 0.045455 intl_equity EWA 0.045455 EWO 0.045455 IEV 0.045455 bond IEF 0.045455 SHY 0.045455 TLT 0.045455 intl_bond BWX 0.045455 BWZ 0.045455 IGOV 0.045455 commodity DBA 0.045455 DBB 0.045455 DBE 0.045455 pe ARCC 0.045455 BX 0.045455 PSP 0.045455 hf DXJ 0.045455 SRV 0.045455 cash BIL 0.045455 GSY 0.045455 Name: 2009-05-15 00:00:00, dtype: float64
如何包含一个额外的限制要求,在将此数据分组时,权重总和落在我预先确定的该资产类别的分配范围之间?
具体来说,我想包含一个额外的边界,使得:
init_weights.groupby(level=0, axis=0).sum()
股票 0.136364 国际股票 0.136364 债券 0.136364 国际债券 0.136364 商品 0.136364 市盈率 0.136364 对冲基金 0.090909 现金 0.090909 dtype: float64
在这些范围内
[(.08,.51), (.05,.21), (.05,.41), (.05,.41), (.2,.66), (0,.16), (0,.76), (0,.11)]
[更新] 我想展示一下我的进展,这是一个笨拙的伪解决方案,我对它并不满意。主要是因为它没有使用整个数据集来解决权重问题,而是按资产类别进行了处理。另一个问题是它返回了系列而不是权重,但我相信比我更能胜任的人可以就groupby函数提供一些见解。
所以通过对我最初的代码进行轻微调整,我有了以下结果:
PortValue = 100000
model = DataFrame(np.array([.08,.12,.05,.05,.65,0,0,.05]), index= port_idx, columns = ['strategic'])
model['tactical'] = [(.08,.51), (.05,.21),(.05,.41),(.05,.41), (.2,.66), (0,.16), (0,.76), (0,.11)]
def fitness(W, Rt):
port_Rt = np.dot(Rt, W)
port_rt = np.log(1 + port_Rt)
q95 = Series(port_rt).quantile(.05)
cVaR = (port_rt[port_rt < q95] * sqrt(20)).mean() * PortValue
mean_cVaR = (PortValue * (port_rt.mean() * 20)) / cVaR
return -1 * mean_cVaR
def solve_weights(Rt, b_= None):
import scipy.optimize as opt
if b_ is None:
b_ = [(0.0, 1.0) for i in Rt.columns]
W = np.ones(len(Rt.columns))/len(Rt.columns)
c_ = ({'type':'eq', 'fun': lambda W: sum(W) - 1})
optimized = opt.minimize(fitness, W, args=[Rt], method='SLSQP', constraints=c_, bounds=b_)
if not optimized.success:
raise ValueError(optimized.message)
return optimized.x # Return optimized weights
以下一行代码将返回较为优化的系列。
port = np.dot(port_rets.groupby(level=0, axis=1).agg(lambda x: np.dot(x,solve_weights(x))),\
solve_weights(port_rets.groupby(level=0, axis=1).agg(lambda x: np.dot(x,solve_weights(x))), \
list(model['tactical'].values)))
Series(port, name='portfolio').cumsum().plot()
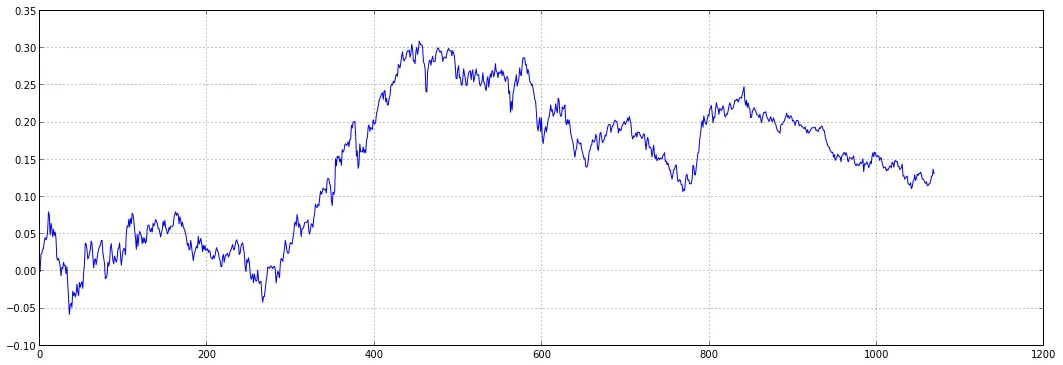
[更新2]
以下更改将返回受限权重,虽然仍不是最优解,因为它被分解和优化为组成资产类别,因此当考虑目标风险约束时,仅可用初始协方差矩阵的折叠版本。
def solve_weights(Rt, b_ = None):
W = np.ones(len(Rt.columns)) / len(Rt.columns)
if b_ is None:
b_ = [(0.01, 1.0) for i in Rt.columns]
c_ = ({'type':'eq', 'fun': lambda W: sum(W) - 1})
else:
covar = Rt.cov()
c_ = ({'type':'eq', 'fun': lambda W: sum(W) - 1},
{'type':'eq', 'fun': lambda W: sqrt(np.dot(W, np.dot(covar, W)) * 252) - risk_tgt})
optimized = opt.minimize(fitness, W, args = [Rt], method='SLSQP', constraints=c_, bounds=b_)
if not optimized.success:
raise ValueError(optimized.message)
return optimized.x # Return optimized weights
class_cont = Rt.ix[0].copy()
class_cont.ix[:] = np.around(np.hstack(Rt.groupby(axis=1, level=0).apply(solve_weights).values),3)
scalars = class_cont.groupby(level=0).sum()
scalars.ix[:] = np.around(solve_weights((class_cont * port_rets).groupby(level=0, axis=1).sum(), list(model['tactical'].values)),3)
return class_cont.groupby(level=0).transform(lambda x: x * scalars[x.name])
BaseException甚至是Exception,最好是使用更具信息性的名称对其进行子类化或使用内置函数。在您的情况下,您可能可以使用ValueError。 - Phillip Cloud