我有一个字典,它包含多个列表,例如:
data = {'a': [80, 130], 'b': [64], 'c': [58,80]}
我该如何将其展开并转换为下面这样的数据框:
data = {'a': [80, 130], 'b': [64], 'c': [58,80]}
我该如何将其展开并转换为下面这样的数据框:
将字典压平的一种选项是
flattened_data = {
k + str(i): x
for k, v in data.items()
for i, x in enumerate(v)
}
{'a0': 80, 'a1': 130, 'b0': 64, 'c0': 58, 'c1': 80}
enumerate(v, 1)而不是enumerate(v)。如果您想在列表仅有单个条目的情况下省略索引,则应该使用for循环而不是字典推导式。使用pd.DataFrame构造函数和GroupBy+cumcount:
data = {'a': [80, 130], 'b': [64], 'c': [58,80]}
df = pd.DataFrame([[k, w] for k, v in data.items() for w in v],
columns=['Index', '0'])
df['Index'] = df['Index'] + (df.groupby('Index').cumcount() + 1).astype(str)
print(df)
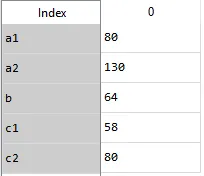
Index 0
0 a1 80
1 a2 130
2 b1 64
3 c1 58
4 c2 80
df = pd.DataFrame([('{}{}'.format(k, i), v1)
if len(v) > 1
else (k, v1)
for k, v in data.items()
for i, v1 in enumerate(v, 1)], columns=['Index','Data'])
print (df)
Index Data
0 a1 80
1 a2 130
2 b 64
3 c1 58
4 c2 80
编辑:
data = {'a': [80, 130], 'b': np.nan, 'c': [58,80], 'd':[34]}
out = []
for k, v in data.items():
if isinstance(v, float):
out.append([k, v])
else:
for i, x in enumerate(v, 1):
if len(v) == 1:
out.append([k, x])
else:
out.append(['{}{}'.format(k, i), x])
print (out)
[['a1', 80], ['a2', 130], ['b', nan], ['c1', 58], ['c2', 80], ['d', 34]]
df = pd.DataFrame(out, columns=['Index','Data'])
print (df)
Index Data
0 a1 80.0
1 a2 130.0
2 b NaN
3 c1 58.0
4 c2 80.0
5 d 34.0
另一种方法是使用from_dict函数,将orient参数设置为'index',并使用stack函数将多级数据压缩成单层,最后使用map和format函数将索引中的多层数据展开:
df = pd.DataFrame.from_dict(data, orient='index')
df_out = df.rename(columns=lambda x: x+1).stack()
df_out.index = df_out.index.map('{0[0]}{0[1]}'.format)
print(df_out)
输出:
a1 80.0
a2 130.0
b1 64.0
c1 58.0
c2 80.0
dtype: float64
使用 itertools 和 pd.io._maybe_dedup_names
x = (itertools.product(s[0],s[1]) for s in data.items())
z = [item for z in x for item in z]
df = pd.DataFrame(z).set_index(0)
df.index = pd.io.parsers.ParserBase({'names':df.index})._maybe_dedup_names(df.index)
1
a 80
a.1 130
b 64
c 58
c.1 80
defaultdict和count。from collections import defaultdict
from itertools import count
c = defaultdict(lambda:count(1))
{f"{k}{['', next(c[k])][len(V) > 1]}": v for k, V in data.items() for v in V}
{'a1': 80, 'a2': 130, 'b': 64, 'c1': 58, 'c2': 80}
enumerate{f"{k}{['', i][len(V) > 1]}": v for k, V in data.items() for i, v in enumerate(V, 1)}
{'a1': 80, 'a2': 130, 'b': 64, 'c1': 58, 'c2': 80}
我认为你应该先获取字典根和字典叶子的列表。
像这样:[a,b,c] 和 [[80,130],[64],[58,80]]
然后只需使用循环并行化它们,以获得
[a1,a2,b,c1,c2] 和 [80,130,64,58,80](这应该只需要几行代码)
然后将其加载到数据框中。
如果您需要更精确的代码,可以提出要求 :)
enumerate的start参数的f-string变体:**{f"{k}{i}": v for k, vs in data.items() for i, v in enumerate(vs, 1)}** - piRSquared{f"{k}{'' if len(vs) == 1 else i}" for k, vs in data.items() for i, v in enumerate(vs, 1)}- piRSquared