如果我的问题已经得到了答复,请接受我的道歉。我试图找到解决方案,但是所有我能找到的都是针对数据帧中所有NaN值的dropna解决方案。 我的问题是,我有一个包含6列和500行的数据帧。我需要检查是否在任何一行中所有的值都是NaN,以便我可以将它们从我的数据集中删除。例如,下面的第2、6和7行从col1到col6都包含所有NaN:
Col1 Col2 Col3 Col4 Col5 Col6
12 25 02 78 88 90
Nan Nan Nan Nan Nan Nan
Nan 35 03 11 65 53
Nan Nan Nan Nan 22 21
Nan 15 93 111 165 153
Nan Nan Nan Nan Nan Nan
Nan Nan Nan Nan Nan Nan
141 121 Nan Nan Nan Nan
请注意,顶部一行只是标题,从第二行开始我的数据才开始。如果有人能帮我指出解决这个谜题的正确方向,我将不胜感激。
另外,我的第二个问题是,在删除所有列中的NaN后,如果我想删除4或5列数据缺失的行,最好的解决方案是什么?
最后一个问题是,如果删除了大多数NaN的行,那么如何在剩余的450行上创建箱线图?
非常感谢您的回复。
敬礼,
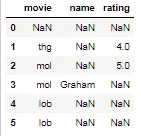
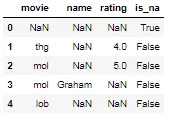
.apply,因为df[cols_to_check].isnull().any(1)的效果完全相同。在一个有200万行数据且有3个需要检查的列的数据框中,使用apply版本需要25.4秒,而使用any只需要106毫秒。 - rpanai