我有一个未知维度空间的点数组,例如:
data=numpy.array(
[[ 115, 241, 314],
[ 153, 413, 144],
[ 535, 2986, 41445]])
我想找出所有点之间的平均欧几里得距离。
请注意,我有超过20,000个点,因此我希望尽可能高效地完成这项任务。
谢谢。
我有一个未知维度空间的点数组,例如:
data=numpy.array(
[[ 115, 241, 314],
[ 153, 413, 144],
[ 535, 2986, 41445]])
我想找出所有点之间的平均欧几里得距离。
请注意,我有超过20,000个点,因此我希望尽可能高效地完成这项任务。
谢谢。
scipy.spatial.distance.cdist(data,data)
嗯,我不认为有一种超快的方法来做到这一点,但是下面这个应该可以:
tot = 0.
for i in xrange(data.shape[0]-1):
tot += ((((data[i+1:]-data[i])**2).sum(1))**.5).sum()
avg = tot/((data.shape[0]-1)*(data.shape[0])/2.)
tot += (...).mean(),和 avg = tot/(data.shape[0]-1)。 - mtrwimport numpy as NP
import numexpr as NE
# data are points in 2D space (x, y)--obviously, this code can accept data of any dimension
x = NP.random.randint(0, 10, 10000)
y = NP.random.randint(0, 10, 10000)
fnx = lambda q : q - NP.reshape(q, (len(q), 1))
delX = fnx(x)
delY = fnx(y)
dist_mat = NE.evaluate("(delX**2 + delY**2)**0.5")
无论如何,评估的数量都是不可避免的:
但如果您能够使用近似结果,则可以节省所有这些平方根的费用。这取决于您的需求。
如果您要计算平均值,我建议在计算之前不要尝试将所有值放入数组中。只需计算总和(如果需要标准差,则还需计算平方和),并在计算每个值时将其丢弃。
由于 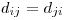 和
和 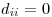 ,我不知道这是否意味着您必须在某个地方乘以二。
,我不知道这是否意味着您必须在某个地方乘以二。
![Sum[n-i, {i, 0, n}] = http://www.equationsheet.com/latexrender/pictures/27744c0bd81116aa31c138ab38a2aa87.gif](http://www.equationsheet.com/latexrender/pictures/27744c0bd81116aa31c138ab38a2aa87.gif){kind=link}