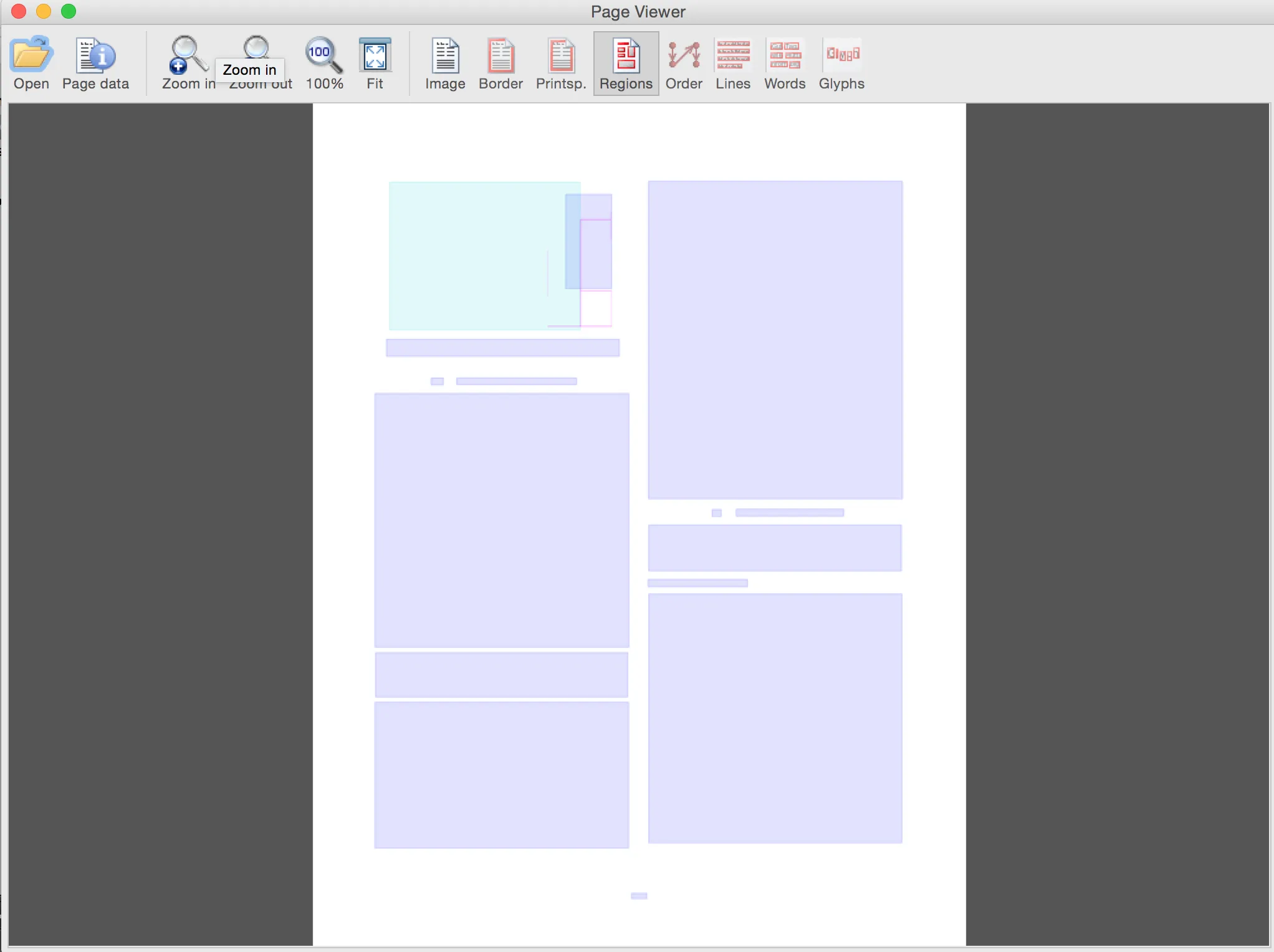
我试图让Tesseract输出一个带有标记的边界框文件,该文件是页面分割(OCR之前)产生的结果。我知道它一定能够在“开箱即用”的情况下做到这一点,因为在ICDAR比赛中展示的结果表明了这一点,参赛者必须对各种文档进行分割(学术论文在此)。以下是论文中的示例,说明了我想要创建的内容:
 我已经使用brew构建了最新版本的Tesseract,
我已经使用brew构建了最新版本的Tesseract,
我已经使用brew构建了最新版本的Tesseract, brew install tesseract --HEAD ,并一直在尝试编辑位于/usr/local/Cellar/tesseract/HEAD/share/tessdata/configs/的配置文件以输出带有标记的框。使用hocr作为配置的输出如下:tesseract infile.tiff outfile_stem -l eng -psm 1 hocr
给出了一切的边界框,并在 class 标签中进行了一些标记。
<p class='ocr_par' dir='ltr' id='par_5_82' title="bbox 2194 4490 3842 4589">
<span class='ocr_line' id='line_5_142' ...
但我无法想象这个过程。是否有标准工具可以可视化hOCR文件,或者在Tesseract中创建带边界框的输出文件的功能已经内置了?
当前版本的详细信息:
tesseract 3.04.00
leptonica-1.71
libjpeg 8d : libpng 1.6.16 : libtiff 4.0.3 : zlib 1.2.5
编辑
我真的很想使用命令行工具来实现这一点(就像上面的例子一样)。@nguyenq已经指向了API参考文档,不幸的是我没有c++经验。如果唯一的解决方法是使用API,请给一个快速的Python示例。
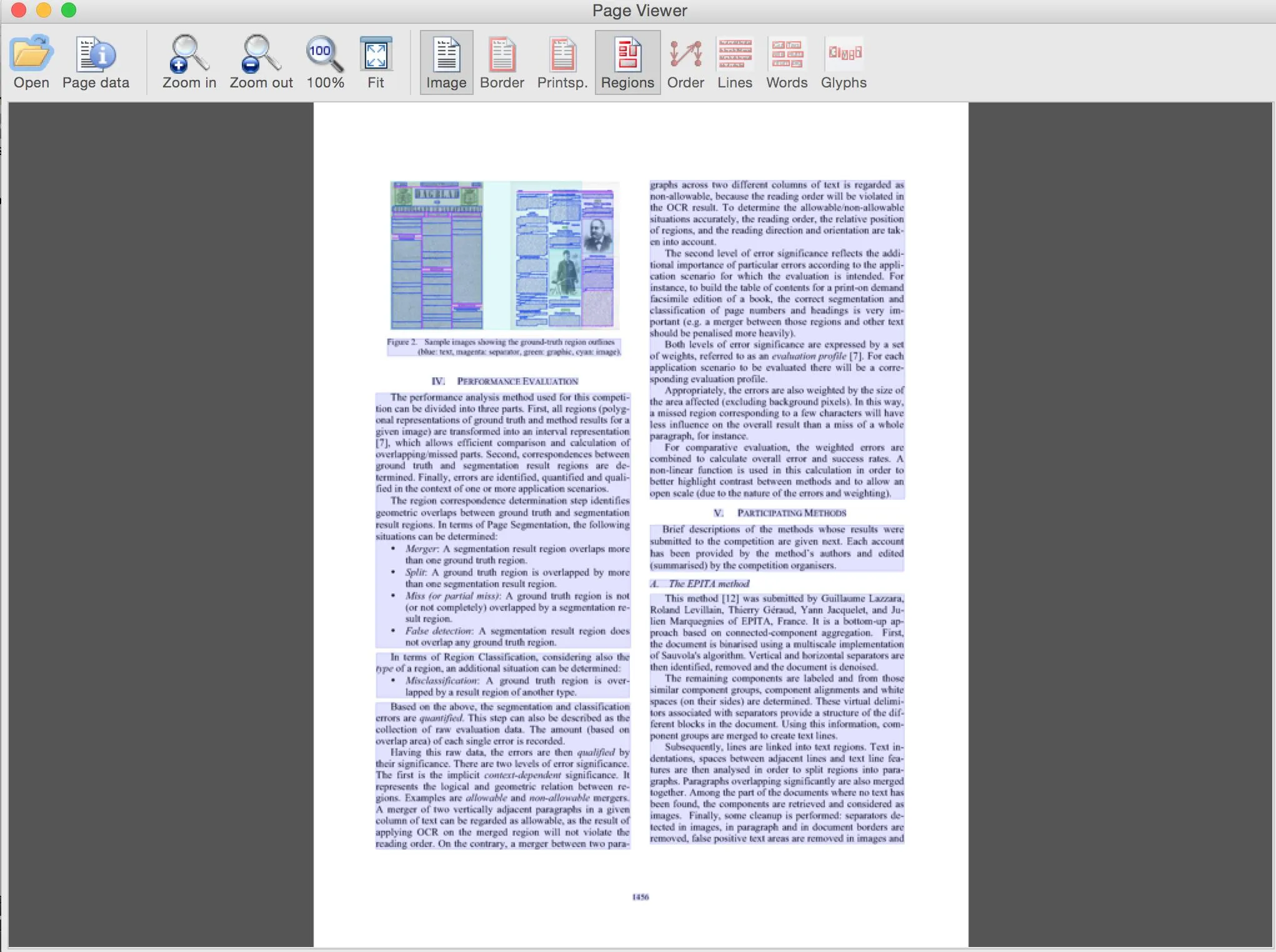 仅叠加层(使用GUI按钮切换)
仅叠加层(使用GUI按钮切换)