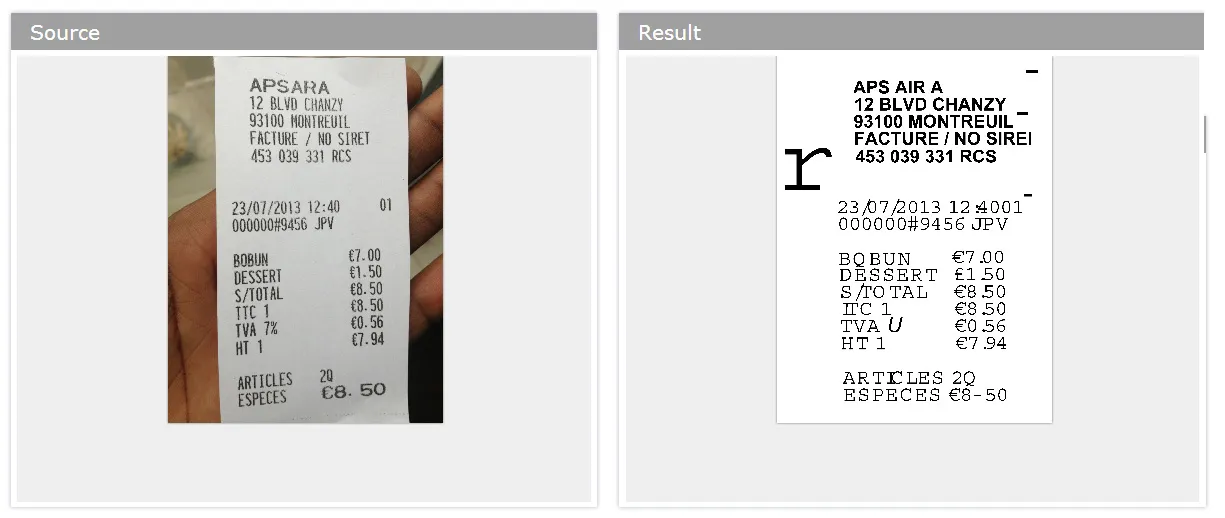
我正在尝试与
我希望它的准确率能达到90%以上。图像的问题在于它们的分辨率为72dpi。我也尝试增加分辨率,但效果不佳,我要识别的图像已经附在下面。
非常感谢您的帮助,如果我问了一些非常基础的问题,请见谅。
tesseract API 进行交互,同时我对图像处理还很陌生,最近几天一直在努力摸索。我尝试了简单的算法,已经取得了约70%的准确率。我希望它的准确率能达到90%以上。图像的问题在于它们的分辨率为72dpi。我也尝试增加分辨率,但效果不佳,我要识别的图像已经附在下面。
非常感谢您的帮助,如果我问了一些非常基础的问题,请见谅。



编辑
我忘记提到我正在尝试在Linux平台上进行所有处理和识别,并且检测此答案中提到的文本的方法需要很长时间,希望在2-2.5秒内完成。此外,我更喜欢不使用命令行解决方案,而是使用Leptonica或OpenCV。
大多数图片上传这里
我已尝试以下方法对票据进行二值化,但没有成功
- http://www.vincent-net.com/luc/papers/10wiley_morpho_DIAapps.pdf
- http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.193.6347&rep=rep1&type=pdf
- http://iit.demokritos.gr/~bgat/PatRec2006.pdf
- http://psych.stanford.edu/~jlm/pdfs/Sternberg67.pdf
票据包含:
- 光线有点暗
- 非文本区域
- 分辨率较低
- 检测图像的边缘
- 使用Blob Analysis进行分析
- 使用自适应阈值对票据进行二值化处理