我正在学习OpenCV和Tesseract,遇到了一个似乎非常简单的例子却遇到了麻烦。
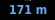
这里有一张我正在尝试OCR的图片,上面写着"171 m":
生成的图像如下所示:
我还尝试了限制可能的字符,情况有所改善,但并不完全。
任何帮助都很感激。
这里有一张我正在尝试OCR的图片,上面写着"171 m":
我进行了一些预处理。由于文本的主色调是蓝色,所以我提取了蓝色通道并应用了简单的阈值处理。
img = cv2.imread('171_m.png')[y, x, 0]
_, thresh = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY_INV)
生成的图像如下所示:
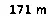
然后将其投入到Tesseract中,使用psm 7进行单行识别:
text = pytesseract.image_to_string(thresh, config='--psm 7')
print(text)
>>> lim
我还尝试了限制可能的字符,情况有所改善,但并不完全。
text = pytesseract.image_to_string(thresh, config='--psm 7 -c tessedit_char_whitelist=1234567890m')
print(text)
>>> 17m
OpenCV v4.1.1.
Tesseract v5.0.0-alpha.20190708
任何帮助都很感激。
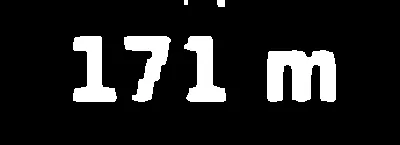
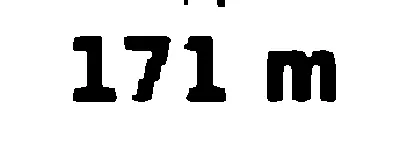

(s, s/2)需要改为(s, int(s/2)),否则会出现TypeError: integer argument expected, got float的错误。 - drec4s