根据使用情况,有多种选项:
如果不知道工作表的名称。
如果工作表的名称不相关。
如果知道工作表的名称。
下面我们将仔细看一下每个选项。
请参见“备注”部分以获取诸如查找工作表名称等信息。
选项1
如果不知道工作表的名称。
df = pd.read_excel('FILENAME.xlsx', sheet_name=None)
print(df.keys())
然后,根据想要读取的表格,可以将它们传递给特定的dataframe,例如:
sheet1_df = pd.read_excel('FILENAME.xlsx', sheet_name=SHEET1NAME)
sheet2_df = pd.read_excel('FILENAME.xlsx', sheet_name=SHEET2NAME)
选项二
如果名称不重要,而且人们只关心表格的位置。假设我们只需要第一个工作表。
df = pd.read_excel('FILENAME.xlsx', sheet_name=None)
sheet1 = list(df.keys())[0]
那么,根据工作表名称,可以将其分别传递给特定的dataframe,例如:
sheet1_df = pd.read_excel('FILENAME.xlsx', sheet_name=SHEET1NAME)
选项三
这里我们将考虑知道工作表名称的情况。
在示例中,我们将假定有三个名为Sheet1、Sheet2和Sheet3的工作表。每个工作表中的内容都相同,并且如下所示
0 1 2
0 85 January 2000
1 95 February 2001
2 105 March 2002
3 115 April 2003
4 125 May 2004
5 135 June 2005
根据目标不同,有多种方法:
sheets = ['Sheet1', 'Sheet2', 'Sheet3']
df = pd.concat([pd.read_excel('FILENAME.xlsx', sheet_name = sheet) for sheet in sheets], ignore_index = True)
[Out]:
0 1 2
0 85 January 2000
1 95 February 2001
2 105 March 2002
3 115 April 2003
4 125 May 2004
5 135 June 2005
6 85 January 2000
7 95 February 2001
8 105 March 2002
9 115 April 2003
10 125 May 2004
11 135 June 2005
12 85 January 2000
13 95 February 2001
14 105 March 2002
15 115 April 2003
16 125 May 2004
17 135 June 2005
基本上,这就是 pandas.concat 的工作方式(来源):
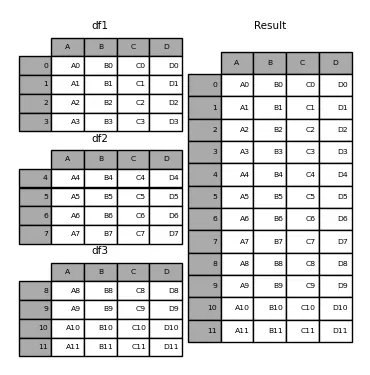
将每个表格存储在不同的数据框中(比如说,df1、df2等)。
sheets = ['Sheet1', 'Sheet2', 'Sheet3']
for i, sheet in enumerate(sheets):
globals()['df' + str(i + 1)] = pd.read_excel('FILENAME.xlsx', sheet_name = sheet)
[Out]:
0 1 2
0 85 January 2000
1 95 February 2001
2 105 March 2002
3 115 April 2003
4 125 May 2004
5 135 June 2005
0 1 2
0 85 January 2000
1 95 February 2001
2 105 March 2002
3 115 April 2003
4 125 May 2004
5 135 June 2005
0 1 2
0 85 January 2000
1 95 February 2001
2 105 March 2002
3 115 April 2003
4 125 May 2004
5 135 June 2005
注意事项:
sheets = pd.ExcelFile('FILENAME.xlsx').sheet_names
[Out]: ['Sheet1', 'Sheet2', 'Sheet3']
在这种情况下,假设文件FILENAME.xlsx和正在运行的脚本位于同一个目录中。
如果文件位于当前目录中名为Data的文件夹中,则可以使用r'./Data/FILENAME.xlsx'创建一个变量,例如path,如下所示:
path = r'./Data/Test.xlsx'
df = pd.read_excel(r'./Data/FILENAME.xlsx', sheet_name=None)
这篇文章可能会对你有所帮助。