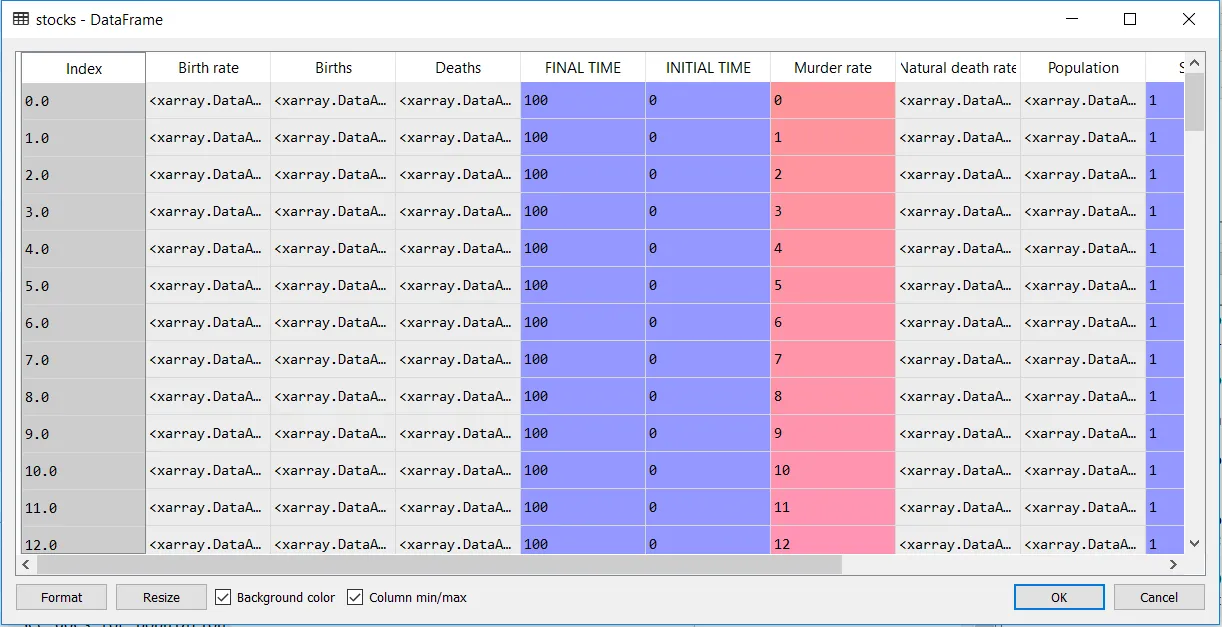
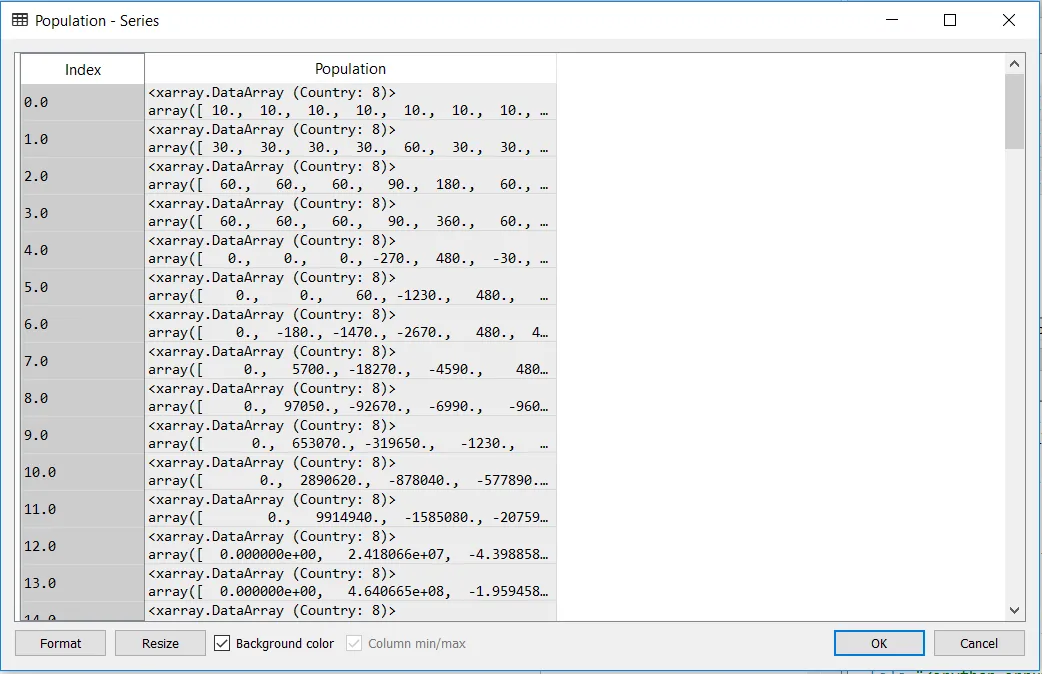
 我正在使用名为PySD的系统动力学建模包。 PySD将来自Vensim(一种系统动力学建模包)的模型转换为Python,并允许用户用比Vensim更复杂的例程替换各种方程。 我正在运行一个带有各种下标的模型,这会创建一种不同寻常的输出格式。 输出被读入数据框架,其下标元素的个别值最终变成xarray.DataArrays。 我想知道如何将xarray.DataArrays的列(最终成为系列)转换为二维数组,其中第二维是下标的数量。
我正在使用名为PySD的系统动力学建模包。 PySD将来自Vensim(一种系统动力学建模包)的模型转换为Python,并允许用户用比Vensim更复杂的例程替换各种方程。 我正在运行一个带有各种下标的模型,这会创建一种不同寻常的输出格式。 输出被读入数据框架,其下标元素的个别值最终变成xarray.DataArrays。 我想知道如何将xarray.DataArrays的列(最终成为系列)转换为二维数组,其中第二维是下标的数量。
import pysd
import numpy as np
model=pysd.load("Example.py")
stocks=model.run
pop=np.array(Population) #Creates an object array
Population=stocks.Populaton #Creates a series
#How to get an array of population values for each country?
示例代码example.py如下(请注意,这只是一个任意的示例,用于说明问题)。
from __future__ import division
import numpy as np
from pysd import utils
import xarray as xr
from pysd.functions import cache
from pysd import functions
_subscript_dict = {
'Country': ['Canada', 'USA', 'China', 'Norway', 'India', 'England',
'Mexico', 'Yemen']
}
_namespace = {
'TIME': 'time',
'Time': 'time',
'Deaths': 'deaths',
'Births': 'births',
'Population': 'population',
'Birth rate': 'birth_rate',
'Murder rate': 'murder_rate',
'Natural death rate': 'natural_death_rate',
'FINAL TIME': 'final_time',
'INITIAL TIME': 'initial_time',
'SAVEPER': 'saveper',
'TIME STEP': 'time_step'
}
@cache('step')
def deaths():
return murder_rate() * population() + natural_death_rate() * population()
@cache('step')
def births():
return birth_rate() * population()
@cache('step')
def population():
return integ_population()
@cache('run')
def birth_rate():
return utils.xrmerge([
xr.DataArray(
data=[5., 5., 5., 5., 5., 5., 5., 5.],
coords={
'Country':
['Canada', 'USA', 'China', 'Norway', 'India', 'England', 'Mexico', 'Yemen']
},
dims=['Country']),
xr.DataArray(data=[10.], coords={'Country': ['Mexico']}, dims=
['Country']),
xr.DataArray(data=[8.], coords={'Country': ['Yemen']}, dims=
['Country']),
])
@cache('step')
def murder_rate():
return time()
@cache('run')
def natural_death_rate():
return utils.xrmerge([
xr.DataArray(
data=[3., 3., 3., 3., 3., 3., 3., 3.],
coords={
'Country':
['Canada', 'USA', 'China', 'Norway', 'India', 'England', 'Mexico', 'Yemen']
},
dims=['Country']),
xr.DataArray(data=[5.], coords={'Country': ['Yemen']}, dims=['Country']),
xr.DataArray(data=[5.], coords={'Country': ['Mexico']}, dims=['Country']),
])
@cache('run')
def final_time():
return 100
@cache('run')
def initial_time():
return 0
@cache('step')
def saveper():
return time_step()
@cache('run')
def time_step():
return 1
def _init_population():
return xr.DataArray(
data=np.ones([8]) * 10,
coords={
'Country': ['Canada', 'USA', 'China', 'Norway', 'India', 'England', 'Mexico', 'Yemen']
},
dims=['Country'])
@cache('step')
def _dpopulation_dt():
return births() - deaths()
integ_population = functions.Integ(lambda: _dpopulation_dt(), lambda: _init_population())
如果example.py文件的制表符不对齐,请谅解。感激任何帮助!