我有一个类似这样的数据框:
dummy = pd.DataFrame([
('01/09/2020', 'TRUE', 'FALSE'),
('01/09/2020', 'TRUE', 'TRUE'),
('02/09/2020', 'FALSE', 'TRUE'),
('02/09/2020', 'TRUE', 'FALSE'),
('03/09/2020', 'FALSE', 'FALSE'),
('03/09/2020', 'TRUE', 'TRUE'),
('03/09/2020', 'TRUE', 'FALSE')], columns=['date', 'Action1', 'Action2'])
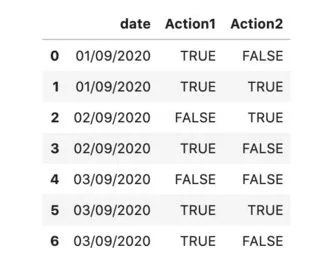
现在我想要每天“TRUE”操作的聚合,应该是这样的:
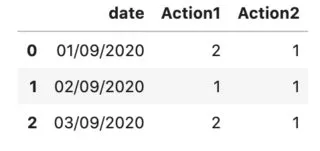
我尝试过使用分组、求和、计数等方式,但是对于需要聚合多个列的情况,这些方法都不管用。我不想将表格拆分成多个数据框并单独解决,然后再合并到一个数据框中,请问有什么聪明的方法可以做到吗?
.resample,因为我们可以将聚合更改为任何时间段。 - Prayson W. Daniel