问题非常简单,但我却找不到足够好的答案。在关于大O符号的最受欢迎的SO问题上说:
我知道最坏情况是
例如,排序算法通常基于比较操作进行比较(比较两个节点以确定它们的相对顺序)。
现在让我们考虑简单的冒泡排序算法:
for (int i = arr.length - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
if (arr[j] > arr[j+1]) {
switchPlaces(...)
}
}
}
我知道最坏情况是
O(n²),而最好情况则是O(n),但是n具体指什么呢?如果我们尝试对已排序的算法进行排序(最好情况),那么我们实际上什么都不需要做,所以为什么它仍然是O(n)呢?我们仍然要遍历两个for循环,所以如果有的话,它应该是O(n²)。n不能表示比较操作的数量,因为我们仍然检查所有元素,对吧?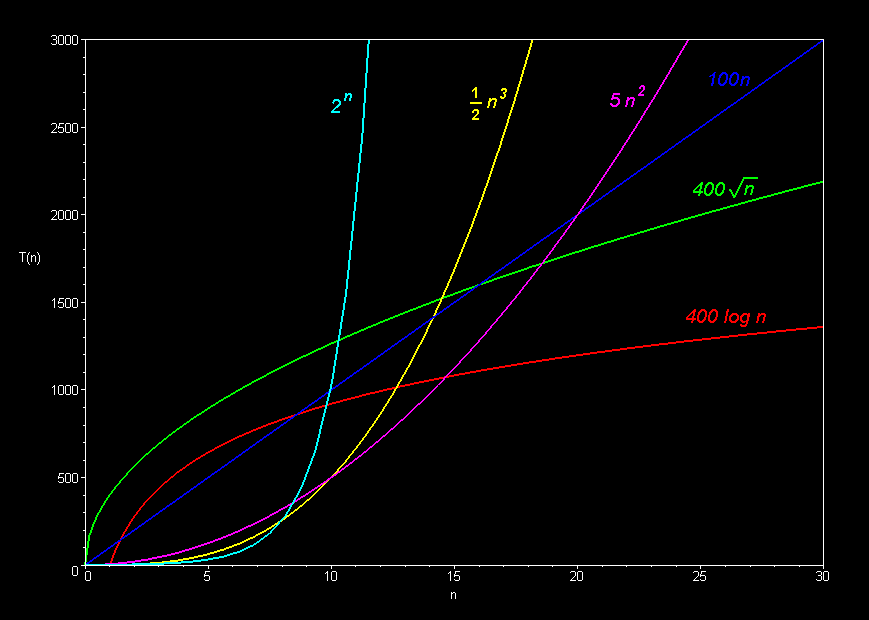
f(n),即N的函数。 - user456814