我希望尽可能少使用正式定义和简单的数学语言。
"Big O"符号的通俗易懂解释是什么?(这是一个关于IT技术的问题)
5359
- Arec Barrwin
10
68摘要:算法复杂度的上限。请参考类似问题Big O,如何计算/近似?以获得良好的解释。 - Kosi2801
7其他答案已经很好了,只有一个细节需要理解:O(log n)或类似的表示它取决于输入的“长度”或“大小”,而不是其本身的值。这可能很难理解,但非常重要。例如,在每次迭代中将算法拆分成两部分时就会出现这种情况。 - Harald Schilly
17麻烦您观看麻省理工学院“计算机科学与编程导论”课程第八讲中关于算法复杂性的演讲,链接为http://www.youtube.com/watch?v=ewd7Lf2dr5Q。该讲座用简单易懂的例子对算法复杂性进行了解释,虽然并非全是简单英语,但仍能清晰地阐述相关概念。 - ivanjovanovic
18大 O 表示算法在最大迭代次数下的最坏情况性能估计。它用于评估函数的表现。 - Paul Sweatte
37作为一名自学编程者,解释“大O符号”: “大O符号”是用于描述算法时间复杂度的记号。它表示算法所需执行基本操作的数量,以输入大小的函数形式表示。例如,在最坏情况下,执行n个元素的线性搜索需要O(n)个操作。这个符号非常有用,因为它可以帮助我们比较和选择不同算法之间的效率。然而,它并不考虑实际运行时间,只关注输入大小对执行时间的影响。 - Soner Gönül
显示剩余5条评论
43个回答
7095
快速提醒一下,我的答案几乎肯定会将“大O符号”(上界)与大Theta符号“Θ”(双侧界)混淆。但据我经验,在非学术场合讨论时这实际上是很常见的。为任何造成的困惑道歉。
这张图可以帮助你直观地理解BigOh复杂度:
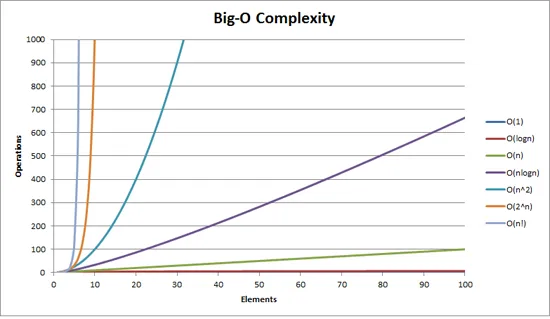
Big Oh符号是算法复杂度的相对表示。
在这个句子中,有一些重要且特意选择的词语:
- 相对:你只能将苹果与苹果进行比较。 你不能将执行算术乘法的算法与对整数列表进行排序的算法进行比较。 但是,比较两个执行算术运算的算法(一个乘法,一个加法)将告诉你一些有意义的东西; - 表示:BigOh(在其最简单的形式中)将算法之间的比较缩减为单个变量。该变量是基于观察或假设选择的。例如,通常基于比较操作(比较两个节点以确定它们的相对顺序)来比较排序算法。 这意味着比较是昂贵的。 但是,如果比较便宜而交换代价高呢? 它会改变比较结果;以及 - 复杂度:如果对10,000个元素进行排序需要1秒钟,那么对100万个元素进行排序需要多长时间? 在这种情况下,复杂度是相对于其他东西的相对度量。
当您阅读完余下内容后,请回到上面再次阅读。
我能想到的最好的BigOh例子是执行算术运算。取两个数字(123456和789012)。 我们在学校中学到的基本算术运算是:
- 加法; - 减法; - 乘法;和 - 除法。
每个都是一个操作或问题。 解决这些问题的方法称为算法。
加法是最简单的。您将数字排成一列(向右),然后在每一列中相加数字,将该加法的最后一位写入结果。该数字的“十位数”会被传递到下一列。
假设这些数字的加法是此算法中最昂贵的操作。很明显,要将这两个数字相加,我们必须相加6个数字(可能还需要进位1个)。如果我们将两个100位数字相加,则必须执行100次加法。如果我们将两个 10,000位数字相加,则必须执行10,000次加法。
看到规律了吗?复杂度(即操作数)与较大数字的位数n成正比。我们称其为O(n)或线性复杂度。
减法类似(除了您可能需要借位而不是进位)。
乘法则有所不同。您排列数字,取底部数字中的第一个数字,依次将其与顶部数字中的每个数字相乘,然后继续处理每个数字。因此,要将我们的两个6位数字相乘,我们必须执行36次乘法。我们可能还需要进行多达10或11次列加以获得最终结果。
如果我们有两个100位数字,我们需要执行10,000次乘法和200次加法。 对于两个一百万位数字,我们需要执行1万亿(10 12 )次乘法和200万次加法。
由于算法与n的平方成比例增长,因此这是O(n²)或二次复杂度。现在是介绍另一个重要概念的好时机:我们只关心复杂度的最显著部分。敏锐的读者可能已经意识到,我们可以将操作数表示为:n²+2n。但正如你从我们处理两个各有一百万位数字的示例中看到的那样,第二项(2n)变得微不足道(在那个阶段仅占总操作数的0.0002%)。
人们可以注意到,我们在这里假设了最坏情况。当乘以6位数字时,如果其中一个数字有4位数,另一个数字有6位数,那么我们只有24次乘法。尽管如此,我们仍然计算该“n”的最坏情况,即当两个数字都是6位数时。因此,大写字母符号表示算法的最坏情况。
电话簿
我能想到的下一个最好的例子就是电话簿,通常称为白页或类似的,但它因国家而异。但我说的是按姓氏列出人名,然后是首字母或名字,可能还有地址和电话号码的电话簿。
现在,如果你要指示计算机在包含100万个姓名的电话簿中查找“John Smith”的电话号码,你会怎么做?忽略你可以猜测S字母从哪里开始(假设你不能),你会怎么做?
一种典型的实现方式可能是打开到中间,取第500,000个并将其与“Smith”进行比较。如果它恰好是“Smith, John”,我们就真的很幸运了。更有可能的是,“John Smith”会在那个名字之前或之后。如果它在后面,那么我们就将电话簿的后半部分分成两半并重复执行。如果在前面,那么我们就将电话簿的前半部分分成两半并重复执行。这就是所谓的“二分查找”,无论你是否意识到,它每天都在编程中使用。
因此,如果你想在一个包含一百万个名字的电话簿中找到一个名字,你最多只需要这样做20次。在比较搜索算法时,我们决定将这种比较称为“n”。
- 对于3个名字的电话簿,最多需要2次比较。 - 对于7个名字的电话簿,最多需要3次比较。 - 对于15个名字的电话簿,最多需要4次比较。 - ... - 对于1,000,000个名字的电话簿,最多需要20次比较。
这真是令人惊叹的好,不是吗?
以BigOh术语来说,这是O(log n)或对数复杂度。现在所讨论的对数可以是ln(基数为e),log10,log2或其他基数。无论如何,它仍然是O(log n),就像O(2n2)和O(100n2)仍然都是O(n2)一样。
值得一提的是,此时可以使用BigOh来确定算法的三种情况:
- 最佳情况:在电话簿搜索中,最佳情况是我们在一次比较中找到了姓名。这是O(1)或常数复杂度;
- 预期情况:如上所述,这是O(log n);以及
- 最坏情况:这也是O(log n)。
回到电话簿。
如果你有一个电话号码,想要找到一个名字呢?警察有一个反向电话簿,但普通公众被拒绝查阅。或者他们可以吗?从技术上讲,您可以在普通电话簿中反向查找号码。怎么做呢?
你从第一个名字开始比较号码,如果匹配就很好,否则你就继续下一个。你必须这样做,因为电话簿是无序的(至少按电话号码)。因此,要根据电话号码查找姓名(反向查找):
最佳情况:O(1);
预期情况:O(n)(对于500,000);和
最坏情况:O(n)(对于1,000,000)。
旅行推销员问题是计算机科学中非常著名的问题。在这个问题中,有N个城镇。每个城镇通过一条特定长度的道路与另外一个或多个城镇相连。旅行推销员问题是找到访问每座城镇的最短路径。
听起来简单?再想想。
如果您有3个城镇A、B和C,并且它们之间都有道路,则可以选择以下路径:
A → B → C A → C → B B → C → A B → A → C C → A → B C → B → A
实际上,这不是所有路径,因为其中一些是等价的(例如,A→B→C和C→B→A是等价的,因为它们使用相同的道路,只是方向相反)。
实际上,只有3种可能性。
带着这个东西去四个城镇,你就有12种可能性(如果我没记错的话)。用5个城镇,则有60种可能性。6个城镇则会有360种可能性。
这实际上是一种名为阶乘的数学运算函数。基本上如下:
5! = 5 × 4 × 3 × 2 × 1 = 120
6! = 6 × 5 × 4 × 3 × 2 × 1 = 720
7! = 7 × 6 × 5 × 4 × 3 × 2 × 1 = 5040
……
25! = 25 × 24 × … × 2 × 1 = 15,511,210,043,330,985,984,000,000
……
50! = 50 × 49 × … × 2 × 1 = 3.04140932 × 10^64
因此,旅行推销员问题的大O表示法是O(n!),或者称为阶乘或组合复杂度。
当你到达200个城镇时,传统计算机没有足够的时间来解决这个问题。
值得思考。
多项式时间
我想快速提到的另一点是,任何复杂度为O(na)的算法都被称为具有多项式复杂度或可以在多项式时间内解决。
O(n)、O(n2)等都属于多项式时间。有些问题无法在多项式时间内解决。因此,世界上使用了一些特殊的东西,公钥加密就是一个典型例子。计算非常大数字的两个质因数是计算上很难的。如果不是这样,我们就不能使用目前的公钥系统。
总之,这就是我对BigOh(修订版)的(希望是通俗易懂的)解释。
- cletus
33
622其他答案聚焦于解释O(1)、O(n^2)等的区别,而你的答案详细阐述了算法如何被分类为n^2、nlog(n)等。对于这个有帮助的回答给予+1,让我更好地理解了大O符号。 - Yew Long
28可以补充一下,大O表示一个上界(由算法给出),大Ω表示一个下界(通常作为与特定算法无关的证明给出),而大Θ表示已知达到该下界的“最优”算法。 - mdm
23如果你想要最长的答案,那么这个很好,但如果你想要用简单的方式来解释Big-O的话,就不太适合了。 - kirk.burleson
180这段话的意思是:这句话“大O表示算法复杂度的相对表达”是绝对错误的。事实上,大O是渐进上界,在计算机科学之外也存在很好的应用。O(n)是线性的,你把大O和theta搞混了。log n 是O(n),1也是O(n)。这个回答(和评论)中混淆Theta和大O的基本错误所获得的赞数相当令人尴尬... - Aryabhatta
77“当你到达200个城镇时,传统计算机已经没有足够的时间来解决这个问题。”宇宙何时将会终结? - Isaac
显示剩余28条评论
809
这段内容展示了算法如何根据输入大小进行伸缩。
O(n2),也称二次复杂度
- 1个项目:1个操作
- 10个项目:100个操作
- 100个项目:10,000个操作
请注意,项目数量增加了10倍,但时间增加了100倍。基本上,当n=10时,O(n2)给我们的是伸缩因子n2,即102。
O(n),也称线性复杂度
- 1个项目:1个操作
- 10个项目:10个操作
- 100个项目:100个操作
这一次,项目数量增加了10倍,所花费的时间也增加了10倍。当n=10时,O(n)的伸缩因子为10。
O(1),也称常数复杂度
- 1个项目:1个操作
- 10个项目:1个操作
- 100个项目:1个操作
项目数量仍然以10倍的速度增加,但O(1)的伸缩因子始终为1。
O(log n),也称对数复杂度
- 1个项目:1个操作
- 10个项目:2个操作
- 100个项目:3个操作
- 1000个项目:4个操作
- 10,000个项目:5个操作
计算量仅按输入值的对数增加。因此,在这种情况下,假设每个计算需要1秒钟,输入n的对数就是所需的时间,因此为log n。
这就是要点。他们简化了数学公式,因此可能不会完全是n2或其他他们所说的那样,但这将成为扩展中占主导地位的因素。
- Ray Hidayat
11
5这个定义确切意思是什么?(项目数量仍以10的倍数增加,但O(1)的缩放因子始终为1。) - Zach Smith
114不是秒数,而是操作次数。另外,你忽略了阶乘时间复杂度和对数时间复杂度。 - Chris Charabaruk
7这段话意思是:这并不好地解释了一个O(n^2)描述的算法可能精确运行在.01n^2 + 999999n + 999999。重要的是要知道算法是使用此标度进行比较,并且当n“足够大”时,比较才有效。Python的timsort实际上对于小数组使用插入排序(最坏/平均情况下O(n^2)),因为它有一个小的开销。 - Casey Kuball
7这个答案混淆了大O符号和Theta符号。对于所有输入都返回1的函数(通常简写为1),实际上属于O(n^2)(即使它也属于O(1))。同样,只需要执行一步且花费恒定时间的算法也被认为是一个O(1)算法,但也被认为是一个O(n)和O(n^2)算法。但是,数学家和计算机科学家可能对定义并没有达成一致。 - Jacob Akkerboom
2此答案中考虑的O(log n)对数复杂度是以10为底的。通常标准是以2为底进行计算。应该记住这一点,不要混淆。另外,正如@ChrisCharabaruk所提到的,复杂度表示的是操作次数而不是秒数。 - akshitmahajan
显示剩余6条评论
445
大 O 符号(也称为“渐进增长”符号)是指在忽略常数因素和接近原点的内容时,函数的“外观”。我们使用它来描述事物的规模如何变化。
基础知识
对于“足够”大的输入...
f(x) ∈ O(upperbound)表示f的增长速度不超过upperboundf(x) ∈ Ɵ(justlikethis)表示f的增长速度与justlikethis相同f(x) ∈ Ω(lowerbound)表示f的增长速度不低于lowerbound
大O符号并不关心常数因子:函数 9x² 被认为“与”10x² 的增长速度相同。大O的渐进符号也不关心非渐进部分(“接近原点的部分”或“问题规模较小时发生的事情”):函数10x²被认为“与”10x²-x+2的增长速度相同。
为什么要忽略方程中的较小部分?因为随着你考虑越来越大的规模,它们被方程中的大部分完全淹没;它们的贡献变得微不足道和无关紧要。(请参见示例部分。)
换句话说,随着输入趋近于无限大,一切都与比率有关。 如果你将实际所需时间除以O(...),在输入足够大的极限情况下,你会得到一个固定因子。 直观来说这很合理:如果能够通过乘以一个函数来获得另一个函数,那么这两个函数就是"相似的"。 这也是我们说...actualAlgorithmTime(N) ∈ O(bound(N))
e.g. "time to mergesort N elements
is O(N log(N))"
这意味着对于“足够大”的问题规模N(如果我们忽略原点附近的内容),存在某个常数(例如2.5,完全是虚构的),使得:
actualAlgorithmTime(N) e.g. "mergesort_duration(N) "
────────────────────── < constant ───────────────────── < 2.5
bound(N) N log(N)
有很多常量选择;通常最好的选择被称为算法的“常数因子”......但我们经常像忽略非最大项一样忽略它(请参阅常数因子部分,了解为什么它们通常不重要)。你也可以将上述方程视为一个界限,即“在最坏情况下,所需时间永远不会比大约N*log(N)更糟糕,差不多是2.5倍(我们不太关心的常数因子)”。
一般来说,O(...)是最有用的,因为我们通常关心最坏情况的行为。如果f(x)代表像处理器或内存使用这样的“坏”东西,则“f(x)∈O(upperbound)”意味着“upperbound是处理器/内存使用的最坏情况”。
应用
作为纯数学概念,大O符号不仅局限于处理时间和内存方面的讨论。可以用它来讨论任何具有可比性的缩放问题,例如:
- 在派对上,
N个人之间可能握手的次数(Ɵ(N²),具体来说是N(N-1)/2,但重要的是它“缩放”像N²一样) - 随着时间的推移,看到某些病毒营销的人数的概率期望值
- 网站延迟随CPU或GPU或计算机集群中处理单元数量的缩放问题
- CPU芯片上的热量输出如何随晶体管数量、电压等因素而缩放
- 算法运行所需时间与输入大小的函数关系
- 算法运行所需空间与输入大小的函数关系
例子
对于上面的握手例子,房间里的每个人都与其他人握手。在这个例子中,#handshakes ∈ Ɵ(N²)。为什么呢?
回到一开始:握手的数量正好是n-choose-2或N*(N-1)/2(每个N个人都要与其他N-1个人握手,但这会重复计算握手次数,所以要除以2):
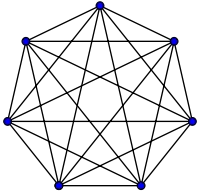

然而,对于非常多的人数,线性项N被忽略了,实际上对比例没有贡献(在图表中:对角线上空格子的比例随着参与者数量的增加而变小)。因此,缩放行为是order N²,或者握手次数“像N²一样增长”。
#handshakes(N)
────────────── ≈ 1/2
N²
我就好像是图表对角线上的空白格子(N*(N-1)/2个勾)不存在一样,(当N趋向于无穷大时,会有N2个勾)。
(从“普通英语”暂时偏离一下:)如果你想要自己证明这个结论,你可以对比率进行一些简单的代数运算,将其分解为多个项(lim表示“在极限情况下考虑”,如果您没有见过它,请忽略它,它只是“当N非常非常大时”的符号表示):
N²/2 - N/2 (N²)/2 N/2 1/2
lim ────────── = lim ( ────── - ─── ) = lim ─── = 1/2
N→∞ N² N→∞ N² N² N→∞ 1
┕━━━┙
this is 0 in the limit of N→∞:
graph it, or plug in a really large number for N
tl;dr:当握手次数很大时,“握手次数”看起来非常像x²,因此,如果我们写下比率#handshakes/x²,即使我们不需要恰好x²次握手,在任意大的时间内,这个事实也不会显示在小数中。
例如,对于x = 100万,比率#handshakes/x²为0.499999 ...
建立直觉
这使我们可以做出像这样的陈述...
“对于足够大的输入大小N,无论常数因子是什么,如果我加倍输入大小...
- ... 我会将O(N)(“线性时间”)算法所需的时间加倍。
N → (2N) = 2(N)
- ... 我会将O(N²)(“二次时间”)算法所需的时间加倍平方(四倍)。”(例如,一个100倍大的问题需要100²=10000倍长的时间...可能不可持续)
N² → (2N)² = 4(N²)
- ... 我会将O(N³)(“三次时间”)算法所需的时间加倍立方(八倍)。”(例如,一个100倍大的问题需要100³=1000000倍长的时间...非常不可持续)
cN³ → c(2N)³ = 8(cN³)
- ... 我会将O(log(N))(“对数时间”)算法所需的时间加上一个固定量。”(便宜!)
c log(N) → c log(2N) = (c log(2))+(c log(N)) = (固定数量)+(c log(N))
- ... 我不会改变O(1)(“常数时间”)算法所需的时间。" (最便宜!)
c*1 → c*1
- ... 我“(基本上)加倍”了O(N log(N))算法所需的时间。" (相当普遍)
c 2N log(2N) / c N log(N) (这里我们将f(2n)/f(n)除以,但我们可以像上面那样操纵表达式并分解出cNlogN)
→ 2 log(2N)/log(N)
→ 2 (log(2) + log(N))/log(N)
→ 2*(1+(log2N)-1) (对于大N基本上为2; 最终小于2.000001)
(或者,说log(N)将始终低于你的数据的17,因此它是线性的;尽管这不严谨也不合理)
- ...我让一个O(2N)("指数时间")算法的时间变得荒谬地增加。" (只需将问题增加一个单位,您就可以将时间翻倍(或翻三倍等))
2N → 22N = (4N)............换句话说......2N → 2N+1 = 2N21 = 22N
[对于数学倾向的人,您可以将鼠标悬停在剧透上以获取次要说明]
(感谢https://dev59.com/-HRB5IYBdhLWcg3w3K0J#487292)
(从技术上讲,在某些更为深奥的示例中,常数因素可能很重要,但是我已经用上面的方式(例如在log(N)中)表述了这些内容,使其不重要)
这些是程序员和应用计算机科学家用作参考点的基本增长顺序。他们经常看到这些。 (因此,虽然您可以从技术上认为“将输入加倍会使O(√N)算法变慢1.414倍”,但最好认为它“比对数更差,但比线性更好”。)
常数因子
通常情况下,我们不关心特定的常数因子,因为它们不会影响函数增长的方式。例如,两个算法可能都需要O(N)时间才能完成,但其中一个可能比另一个慢两倍。除非因子非常大,否则我们通常不会太在意,因为优化是棘手的问题(什么时候进行过度优化?);此外,仅仅选择一个具有更好的大O算法通常就能将性能提高几个数量级。
一些渐进上优的算法(例如非比较的O(Nlog(log(N)))排序)可能具有如此巨大的常数因子(例如100000*N log(log(N))),或者相对较大的开销,例如隐含的+ 100*N 的 O(Nlog(log(N))),即使在“大数据”上使用也很少值得使用。
为什么O(N)有时是你所能做到的最好算法,即为什么我们需要数据结构
如果您需要读取所有数据,则O(N)算法在某种意义上是“最佳”算法。阅读一堆数据的行为本身就是一个O(N)操作。将其加载到内存中通常是O(N)(如果您具有硬件支持,则更快,或者如果您已经读取了数据,则根本不需要时间)。但是,如果您触摸甚至查看每个数据片段(甚至是每个其他数据片段),则您的算法将花费O(N)时间来执行此查看。无论实际算法花费多长时间,它都至少需要O(N),因为它花费了时间查看所有数据。
对于写入行为本身也可以说同样的事情。所有打印出N个东西的算法都需要N的时间,因为输出至少那么长(例如,打印出N张纸牌的所有排列方式是阶乘:O(N!)(这就是为什么在这些情况下,好的程序将确保迭代使用O(1)内存并且不会打印或存储每个中间步骤)。
O(N)时间),加上一些任意数量的预处理(例如O(N)或O(N log(N))或O(N²)),我们尝试保持尽可能小。此后,对数据结构进行修改(插入/删除/等)和对数据进行查询所需的时间非常短,例如O(1)或O(log(N))。然后,您可以继续进行大量的查询!一般来说,您愿意提前做的工作越多,以后就要做的工作就越少。
例如,假设您拥有数百万个道路段的纬度和经度坐标,并希望找到所有街道交叉口。
- 朴素方法:如果您有街道交叉口的坐标,并想要检查附近的街道,每次都必须遍历数百万条路段,并检查每一条路段是否相邻。
- 如果只需要执行一次此操作,则使用朴素方法进行
O(N)工作不是问题,但如果您要执行多次(在本例中,每个段都需要执行一次),我们将需要执行O(N²)的工作量,即1000000² = 1000000000000次操作。这不好(现代计算机每秒可以执行约十亿次操作)。 - 如果我们使用一个名为哈希表的简单结构(一种即时速度的查找表,也称为哈希映射或字典),我们通过以
O(N)的时间预处理所有内容来支付一定的成本。此后,平均情况下只需恒定时间就可以通过键查找某些内容(在本例中,我们的键是经纬度坐标,四舍五入到网格中;我们搜索仅有9个相邻网格空间,这是一个常数)。 - 我们的任务从无法实现的
O(N²)变为可管理的O(N),而我们所做的只是支付了少量成本以创建哈希表。 - 类比:在这种情况下的类比是拼图游戏:我们创建了一种数据结构,利用了数据的某些属性。如果我们的路段就像拼图块一样,我们通过匹配颜色和图案将它们分组。然后,我们利用这一点避免以后做额外的工作(将相似颜色的拼图块相互比较,而不是与每个单独的拼图块相互比较)。
实际例子:编写代码时可视化增长量
渐进符号是一个数学框架,用于思考事物的规模,可以应用于许多不同的领域,与编程本质上是相互独立的。尽管如此...这就是您如何将渐进符号应用于编程。
基础知识:每当我们与大小为 A 的集合中的每个元素进行交互(例如,数组、集合、映射的所有键等),或执行 A 次循环迭代时,这都是大小 A 的乘性因子。为什么我说“乘性因子”?--因为循环和函数(几乎是定义)具有乘性运行时间:迭代次数乘以循环内部的工作量(或者对于函数而言:调用函数的次数乘以函数内部的工作量)。 (如果我们不做任何花哨的事情,比如跳过循环或提前退出循环,或者根据参数改变函数的控制流,这非常常见。)以下是一些可视化技术示例,附带伪代码。
(在这里,“x”表示常量时间单位的工作量,处理器指令,解释器操作码,或其他类似内容)
for(i=0; i<A; i++) // A * ...
some O(1) operation // 1
--> A*1 --> O(A) time
visualization:
|<------ A ------->|
1 2 3 4 5 x x ... x
other languages, multiplying orders of growth:
javascript, O(A) time and space
someListOfSizeA.map((x,i) => [x,i])
python, O(rows*cols) time and space
[[r*c for c in range(cols)] for r in range(rows)]
例子2:
for every x in listOfSizeA: // A * (...
some O(1) operation // 1
some O(B) operation // B
for every y in listOfSizeC: // C * (...
some O(1) operation // 1))
--> O(A*(1 + B + C))
O(A*(B+C)) (1 is dwarfed)
visualization:
|<------ A ------->|
1 x x x x x x ... x
2 x x x x x x ... x ^
3 x x x x x x ... x |
4 x x x x x x ... x |
5 x x x x x x ... x B <-- A*B
x x x x x x x ... x |
................... |
x x x x x x x ... x v
x x x x x x x ... x ^
x x x x x x x ... x |
x x x x x x x ... x |
x x x x x x x ... x C <-- A*C
x x x x x x x ... x |
................... |
x x x x x x x ... x v
例子3:
function nSquaredFunction(n) {
total = 0
for i in 1..n: // N *
for j in 1..n: // N *
total += i*k // 1
return total
}
// O(n^2)
function nCubedFunction(a) {
for i in 1..n: // A *
print(nSquaredFunction(a)) // A^2
}
// O(a^3)
如果我们做一些稍微复杂的事情,你可能仍然能够在视觉上想象出正在发生的事情:
for x in range(A):
for y in range(1..x):
simpleOperation(x*y)
x x x x x x x x x x |
x x x x x x x x x |
x x x x x x x x |
x x x x x x x |
x x x x x x |
x x x x x |
x x x x |
x x x |
x x |
x___________________|
这里,你能画出的最小可识别轮廓是有意义的;三角形是二维形状(0.5 A^2),就像正方形是二维形状(A^2)一样;这里的两个常数因子在它们之间的渐近比率中保持不变,但是,我们像所有因素一样忽略它...(这种技术存在一些不幸的细微差别,我不在这里详细说明;它可能会误导你。)
当然,这并不意味着循环和函数是不好的;相反,它们是现代编程语言的构建块,我们喜欢它们。然而,我们可以看到,我们将循环、函数和条件与我们的数据(控制流等)编织在一起的方式模仿了我们程序的时间和空间使用!如果时间和空间使用成为问题,那么我们就会寻求巧妙之处,并找到一种简单的算法或数据结构,以某种方式减少增长次序。尽管这些可视化技术(虽然它们并不总是有效)可能会给出一个最坏情况运行时间的天真猜测。
这里还有另一件事情,我们可以从视觉上识别:
<----------------------------- N ----------------------------->
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x
x x x x x x x x x x x x x x x x
x x x x x x x x
x x x x
x x
x
我们可以重新排列这个公式来看出它的时间复杂度为O(N):
<----------------------------- N ----------------------------->
x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x
x x x x x x x x x x x x x x x x|x x x x x x x x|x x x x|x x|x
或者你可以对数据进行log(N)次操作,总时间复杂度为O(N*log(N)):
<----------------------------- N ----------------------------->
^ x x x x x x x x x x x x x x x x|x x x x x x x x x x x x x x x x
| x x x x x x x x|x x x x x x x x|x x x x x x x x|x x x x x x x x
lgN x x x x|x x x x|x x x x|x x x x|x x x x|x x x x|x x x x|x x x x
| x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x|x x
v x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x|x
不相关但值得再次提到的是:如果我们执行哈希(例如字典/哈希表查找),那么时间复杂度为O(1)。这相当快。
[myDictionary.has(x) for x in listOfSizeA]
\----- O(1) ------/
--> A*1 --> O(A)
如果我们做一些非常复杂的事情,比如使用递归函数或分治算法,你可以使用主定理(通常有效),或者在极端情况下使用Akra-Bazzi定理(几乎总是有效)来查找算法的运行时间。但是,程序员不会这样想,因为最终,算法直觉就变成了第二天性。您将开始编写一些效率低下的代码,并立即思考“我是否正在做一些极其低效的事情?”如果答案是“是”,并且您预见到它实际上很重要,那么您可以退后一步,考虑各种技巧来使事情更快地运行(答案几乎总是“使用哈希表”,很少是“使用树”,而且很少是一些更复杂的东西)。
摊销和平均情况复杂度
还有"摊销"和/或"平均情况"的概念(请注意这些是不同的)。
平均情况:这只是使用大O符号来表示函数的期望值,而不是函数本身。在通常情况下,您认为所有输入都是等可能的,平均情况只是运行时间的平均值。例如,在快速排序中,即使最坏情况是对于一些非常糟糕的输入O(N^2),平均情况仍然是通常的O(N log(N))(非常糟糕的输入数量很少,我们在平均情况下几乎不会注意到它们)。
O(1)时间。然而,偶尔它会“打嗝”,并且需要O(N)时间进行一次随机操作,因为可能需要进行一些簿记或垃圾回收等操作...但是它向您承诺,如果它打嗝了,它不会再打嗝了N次操作。每个操作的最坏情况成本仍然是O(N),但在多次运行中的摊销成本为O(N)/N=O(1)每个操作。由于大型操作非常罕见,因此偶尔的大量工作可以被视为与其余工作混合在一起的常数因子。我们说工作在足够多次调用中“摊销”后,在渐近意义下消失。
摊销分析的类比:
你开车。偶尔,您需要花费10分钟去加油站,然后花费1分钟加满油箱。如果您每次开车都这样做(花费10分钟驾车到加油站,花费几秒钟加满一加仑),那将非常低效。但是,如果您每隔几天就加满一次油箱,则花费11分钟驾车到加油站就会“摊销”在足够多的行程中,您可以忽略它,并假装所有行程可能会长5%。
平均情况和摊销最坏情况的比较:
- 平均情况:我们对输入做出一些假设;例如,如果我们的输入具有不同的概率,则我们的输出/运行时间将具有不同的概率(我们取平均值)。通常,我们假设我们的输入是均等的(均匀概率),但如果实际输入不符合我们的“平均输入”假设,则平均输出/运行时间计算可能没有意义。但是,如果您预计输入是均匀随机的,则考虑这一点是有用的!
- 摊销最坏情况:如果您使用摊销最坏情况的数据结构,则性能保证在摊销最坏情况范围内...最终(即使输入由知道所有信息并试图欺骗您的邪恶恶魔选择)。通常,我们使用此方法来分析在性能上可能非常“颠簸”的算法,出现意外的大幅波动,但随着时间的推移,它们的表现与其他算法一样好。(但是,除非您的数据结构对于需要拖延的未完成工作有上限,否则恶意攻击者可能会迫使您一次性赶上最大量的拖延工作。
虽然,如果您合理担心攻击者,除了摊销和平均情况之外,还有许多其他算法攻击向量需要担心。
平均情况和摊销都是设计时考虑可扩展性非常有用的工具。
(如果对此子主题感兴趣,请参见平均情况和摊销分析之间的区别。)
多维大O表示法
大多数情况下,人们没有意识到有多个变量在起作用。例如,在字符串搜索算法中,您的算法可能需要时间 O([文本长度]+[查询长度]),即它是两个变量的线性函数,如 O(N+M)。其他更为天真的算法可能是 O([文本长度]*[查询长度]) 或 O(N*M)。忽略多个变量是我在算法分析中看到的最常见的疏忽之一,这可能会妨碍您设计算法。
整个故事
请记住,大O并不是整个故事。您可以通过使用缓存、使它们成为缓存无关的算法、通过使用RAM而不是磁盘来避免瓶颈、使用并行化或提前完成工作等技术来大大加快某些算法的速度 - 尽管这些技术通常与生长阶数“大O”符号无关,但您经常会在并行算法的大O符号中看到核心数量。
还要记住,由于程序的隐藏约束条件,您可能真的不关心渐近行为。例如,您可能正在处理有限数量的值:
- 如果您正在对5个元素之类的东西进行排序,则不希望使用快速的
O(N log(N))快速排序;您希望使用插入排序,在小输入上表现良好。这些情况经常在分治算法中出现,其中将问题分解为越来越小的子问题,例如递归排序、快速傅里叶变换或矩阵乘法。 - 如果由于某些隐藏事实(例如,平均人名软性边界可能为40个字母,人类年龄软性边界约为150),某些值实际上是有界的。您还可以对输入施加限制,以有效地使术语恒定。
实际上,即使在具有相同或类似渐近性能的算法中,它们的相对优点实际上可能受到其他因素的驱动,例如:其他性能因素(快速排序和归并排序都是O(N log(N)),但快速排序利用了CPU缓存);非性能考虑因素,如易于实现;是否可用库以及库的声誉和维护情况。
以上问题(例如选择使用哪种编程语言的影响)几乎从不被视为常数因素的一部分(也不应该是);但是应该意识到它们,因为有时候(虽然很少)它们可能会影响事情。例如,在cpython中,本地优先队列实现在渐近意义上不是最优的(
O(log(N))而不是O(1)用于插入或查找最小值);你会使用另一种实现吗?可能不会,因为C实现可能更快,而且其他地方可能也存在类似的问题。存在权衡;有时它们很重要,有时它们不重要。
(编辑: 这里的“简明英语”解释到此为止。)
数学附录
为了完整起见,大O符号的精确定义如下: f(x) ∈ O(g(x)) 意味着"f在常数*g的渐进上界之内":忽略x的某个有限值以下的一切,存在一个常数,使得 |f(x)| ≤ const * |g(x)|。(其他符号如下: 就像O表示≤,Ω表示≥。有小写变体: o表示<,ω表示>.) f(x) ∈ Ɵ(g(x)) 意味着既有 f(x) ∈ O(g(x)) 又有 f(x) ∈ Ω(g(x)) (上下由g界定): 存在某些常数,使得f将始终处于const1*g(x)和const2*g(x)之间的“带状区域”中。这是你可以做出的最强渐近语句,大致相当于==。(对不起,我决定推迟绝对值符号的提及,为了清晰起见;特别是因为我从未见过在计算机科学上下文中出现负值。)
= O(...),这可能是更正确的“计算机科学”符号,并且完全可以使用;"f = O(...)"被读作"f is order ... / f is xxx-bounded by ...",并被认为是"f is some expression whose asymptotics are ..."。我被教导使用更严格的∈ O(...)。∈意味着"is an element of"(仍然如前所述)。在这种特殊情况下,O(N²)包含像{2 N²,3 N²,1/2 N²,2 N² + log(N),- N² + N^1.9,...}这样的元素,它是无限大的,但它仍然是一个集合。O和Ω不是对称的(n = O(n²),但n²不是O(n)),但Ɵ是对称的,并且(由于这些关系都是传递和自反的)Ɵ因此是对称、传递和自反的,因此将所有函数的集合划分为等价类。等价类是我们认为相同的一组事物。也就是说,给定任何你能想到的函数,你都可以找到一个规范/唯一的“渐近代表”类(通常通过取极限...我认为);就像你可以将所有整数分成奇数或偶数一样,你可以将所有具有Ɵ的函数分组为x-ish、log(x)^2-ish等...通过基本忽略较小的项(但有时你可能会被更复杂的函数所困扰,它们是单独的类)。 < p >“= ”符号可能更常见,甚至被世界著名的计算机科学家在论文中使用。此外,在非正式场合,人们通常会说
O(...) 当他们想表达 Ɵ(...) 时; 这在技术上是正确的,因为 Ɵ(exactlyThis) 的集合是 O(noGreaterThanThis) 的子集...并且更容易输入。;-)< / p>
- ninjagecko
9
33一个出色的数学回答,但是OP要求一个简单易懂的英语回答。尽管理解这个答案并不需要这种数学描述,但对于特别善于数学的人来说,这可能比“纯英语”更容易理解。然而,OP要求后者。 - El Zorko
45除了原帖作者外,可能还有其他人对这个问题的答案感兴趣。这不是该网站的指导原则吗? - Casey
7尽管我可以理解人们为什么可能会浏览我的回答并认为它过于数学化(尤其是那些“数学是新的普通英语”的讽刺言论,已经被移除),但原始问题询问的是大O符号,涉及函数,因此我试图明确地谈论函数,并以一种补充通俗易懂直觉的方式表达。这里的数学内容经常可以略过,或者可以通过高中数学背景理解。然而,我觉得人们可能会看望结尾的数学附录,并认为那是答案的一部分,而实际上只是为了展示真正的数学长什么样子。 - ninjagecko
5这是一个非常棒的答案,我认为比得票最高的答案要好得多。所需的“数学”并不超出理解在“O”后面括号中表达式所需的范围,任何使用示例的合理解释都无法避免。 - Dave Abrahams
2"f(x) ∈ O(upperbound)" 的意思是 f "不会增长得比" upperbound 更快。这三个简单但数学上正确的 big Oh、Theta 和 Omega 的解释是非常宝贵的。他用通俗易懂的语言向我解释了这一点,而其他五个来源似乎无法在不写复杂的数学表达式的情况下将其翻译给我。谢谢你! :) - timbram
显示剩余4条评论
256
编辑说明:快速提醒,这几乎肯定会混淆大O符号(它是一个上限)和Theta符号(它是上限和下限)。 根据我的经验,这在非学术环境中的讨论中实际上是很典型的。对于造成的任何困惑,请接受道歉。
简而言之:随着工作规模的增加,完成工作需要多长时间?
显然,这仅使用“大小”作为输入和“花费的时间”作为输出-如果您想谈论内存使用等,则适用相同的思想。
这里是一个例子,我们有N件T恤需要晾干。 我们将假设将它们放在晾衣架上的速度非常快(即人类互动可忽略不计)。 当然,在现实生活中并非如此...
使用室外晾衣绳:假设您拥有一个无限大的后院,洗涤物在O(1)时间内变干。不管你有多少衣服,它们都会得到同样的阳光和新鲜空气,所以大小不影响干燥时间。
使用烘干机:每次可以放10件衬衫,然后它们在一小时后就完成了。(忽略实际数字——它们是无关紧要的。)因此,干燥50件衬衫需要大约5倍于干燥10件衬衫的时间。
把所有衣服放在烘箱里:如果我们把所有衣服堆在一起,让周围的温暖做事情,中间的衬衫就需要很长时间才能变干。我不想猜测细节,但我认为这至少是O(N^2)——随着洗涤物负荷的增加,干燥时间增加得更快。
这是否意味着哈希表比数组更快?未必如此。如果您只有很少的条目集合,那么数组可能会更快 - 您可以在检查所有字符串的时间内完成操作,而不仅仅是计算正在查看的字符串的哈希码所需的时间。然而,随着数据集变得越来越大,哈希表最终将击败数组。"
- Jon Skeet
7
6哈希表需要运行一个算法来计算实际数组的索引(根据实现方式而定)。而数组只有 O(1) 的时间复杂度,因为它只是一个地址。但这与问题无关,只是一种观察 :) - Filip Ekberg
7Jon的解释与问题有很大关系,我认为这正是我们向母亲解释问题的方式,她最终会理解的:) 我喜欢衣服的例子(特别是最后一个,它解释了复杂度的指数增长)。 - Johannes Schaub - litb
4菲利普:我不是在谈论按索引访问数组,我是在谈论在数组中查找匹配的条目。你能重新阅读回答并看看是否仍然不清楚吗? - Jon Skeet
3我认为你在想直接寻址表,每个索引直接映射到一个键,因此是O(1),然而我相信Jon正在谈论一个未排序的键/值对数组,你需要线性搜索。 - ljs
2@RBT:不,这不是二进制查找。它可以立即到达正确的哈希桶,仅基于从哈希码到桶索引的转换。之后,在桶中找到正确的哈希码可能是线性的,也可能是二分查找...但此时您已经降低到字典总大小的非常小的比例。 - Jon Skeet
显示剩余2条评论
137
大O描述了一个函数增长行为的上限,例如程序运行时间,当输入变得很大时。
例子:
O(n):如果我将输入大小加倍,则运行时间加倍
O(n2):如果输入大小加倍,则运行时间增加四倍
O(log n):如果输入大小加倍,则运行时间增加一倍
O(2n):如果输入大小增加一,则运行时间加倍
输入大小通常是表示输入所需的位数。
- starblue
5
7错误!举个例子:O(n):如果我将输入大小加倍,运行时会乘以有限的非零常数。我的意思是 O(n) = O(n + n)。 - arena-ru
7我所说的是 f(n) = O(g(n)) 中的 f,而不是你似乎理解的 g。 - starblue
我点了赞,但是我感觉最后一句话没有太多贡献。当我们讨论或测量大O时,我们很少谈论“位”。 - cdiggins
5你应该为O(n log n)添加一个示例。 - Christoffer Hammarström
这并不是很清楚,本质上它的表现比O(n)略差一些。因此,如果n加倍,运行时间将乘以一个略大于2的因子。 - starblue
112
大O符号最常被程序员用来近似衡量计算(算法)需要多长时间才能完成,这个时间将作为输入集大小的函数来表示。
当输入数量增加时,使用大O符号可以比较两种算法的扩展效果。
更精确地说,大O符号 用于表示函数的渐近行为,即函数在趋向无穷大时的行为。
在很多情况下,一个算法的“O”会属于以下几种情况之一:
- O(1) - 完成所需的时间不受输入集大小的影响。例如,通过索引访问数组元素。
- O(Log N) - 完成所需的时间与log2(n)大致成比例增加。例如,1024个项需要的时间大约是32个项的两倍,因为Log2(1024) = 10而Log2(32) = 5。一个例子是在二叉搜索树(BST)中查找项。
- O(N) - 完成所需的时间与输入集大小线性扩展。换句话说,如果您将输入集中的项目数量加倍,则算法所需的时间大约增加一倍。一个例子是计算链接列表中的项目数。
- O(N Log N) - 完成所需的时间按项目数乘以Log2(N)的结果增加。这种情况的例子是堆排序和快速排序。
- O(N^2) - 完成所需的时间大致等于项数的平方。这种情况的例子是冒泡排序。
- O(N!) - 完成所需的时间是输入集的阶乘。这种情况的例子是旅行商问题暴力解。
大O符号忽略那些在输入大小趋近于无穷大时对函数增长曲线没有实质性贡献的因素。这意味着添加到函数中的常数或乘积将被简单地忽略。
- cdiggins
3
cdiggins,如果我的复杂度是O(N/2),那么它应该是O(N)还是O(N/2)?例如,如果我只循环字符串的一半,它的复杂度是多少? - Melad Basilius
1@Melad 这是一个常量(0.5)乘以函数的示例。由于在 N 取很大值时,它被认为没有实际意义而被忽略。 - cdiggins
我喜欢这个答案,因为它将每个BigO与一些例子(如数据结构或算法常见问题)联系起来。 - danfromisrael
90
Big O是一种“表达”代码“需要多长时间/空间来运行”的通用方法。
你经常会看到O(n),O(n2),O(nlogn)等等,所有这些只是展示算法如何变化的方式。
O(n)表示Big O是n,现在你可能会想,“什么是n!?”那么“n”是元素的数量。比如,如果你想在数组中搜索一个项目,你必须检查每个元素并问“你是正确的元素/项目吗?”在最坏的情况下,该项在最后一个索引处,这意味着它花费了与列表中的项目相同的时间,为了具有普遍性,我们说“嘿,n是一个公平给定的值!”
那么你也许可以理解“n2”的含义,但更加具体地说,想象一下你有一个简单的、最简单的排序算法;冒泡排序。这个算法需要查看整个列表的每个项目。
我的列表
- 1
- 6
- 3
流程如下:
- 比较1和6,哪个更大?好的,6在正确的位置上,往前走!
- 比较6和3,哦,3更小!我们把它移动一下,好的,列表发生了变化,我们现在需要从头开始!
这是O n2,因为你需要查看列表中的所有项目,有“n”个项目。对于每个项目,你需要再次查看所有项目进行比较,这也是“n”,所以对于每个项目,你要查看“n”次,意味着n*n=n2
我希望这就是你想要的简单。
但是请记住,Big O只是一种表达时间和空间的方式。
- Filip Ekberg
58
Big O描述算法的基本缩放特性。
Big O并不能告诉你关于给定算法的所有信息。它仅提供有关算法缩放特性的信息,具体来说,算法的资源使用(例如时间或内存)如何根据“输入大小”缩放。
考虑蒸汽机和火箭之间的区别。它们不仅仅是同一种类型的不同变体(例如Prius发动机与兰博基尼发动机),而是在其核心处具有截然不同的推进系统。蒸汽机可能比玩具火箭快,但是没有蒸汽活塞发动机能够达到轨道运载器的速度。这是因为这些系统具有不同的缩放特性,涉及到达到给定速度(“输入大小”)所需燃料(“资源使用”)的关系。
为什么这么重要?因为软件处理的问题可能相差数十亿倍。想一想这个比例。旅行到月球所需的速度与人类步行速度之间的比率小于10,000:1,与软件可能面临的输入大小范围相比,这绝对微不足道。由于软件可能面临广泛的输入大小范围,因此算法的Big O复杂度,即其基本缩放特性,可能会超越任何实现细节。
考虑典型的排序示例。冒泡排序是O(n 2),而归并排序是O(n log n)。假设您有两个排序应用程序,应用程序A使用冒泡排序,应用程序B使用归并排序,并且对于约30个元素的输入大小,应用程序A在排序方面比应用程序B快1000倍。如果您永远不必排序超过30个元素,那么显然应该选择应用程序A,因为它在这些输入大小上要快得多。但是,如果您发现需要对一千万个项目进行排序,则您预计在这种情况下,由于每种算法的缩放方式不同,应用程序B实际上比应用程序A快数千倍。
- Wedge
46
这里是我通常使用的英文动物园,用于解释Big-O的常见变种
在所有情况下,都优先选择列表中更高的算法。然而,将成本提高到更昂贵的复杂度类别的成本差异很大。
O(1):
没有增长。无论问题有多大,您都可以在相同的时间内解决它。这与广播有些类似,在广播距离范围内的人数不考虑大小时,需要相同的能量。
O(log n):
这种复杂度与 O(1)相同,只是稍微糟糕一点。在所有实际目的中,您可以将其视为非常大的常数缩放。处理1千个和10亿个项目之间的工作差异仅为六倍。
O(n):
解决问题的成本与问题的规模成比例。如果问题大小加倍,则解决方案的成本也加倍。由于大多数问题都必须以某种方式扫描到计算机中,例如数据输入、磁盘读取或网络流量,因此这通常是一种可行的缩放因子。
O(n log n):
这种复杂度与 O(n)非常相似。在所有实际目的中,这两者是等效的。这个复杂度级别通常仍被认为是可扩展的。通过调整假设,一些 O(n log n)算法可以转化为 O(n)算法。例如,限制键的大小将排序从 O(n log n)减少到 O(n)。
O(n2):
增长是按照正方形的方式进行,其中n是正方形边长。这与"网络效应"的增长率相同,即网络中的每个人可能都认识网络中的其他人。增长是昂贵的。大多数可扩展解决方案无法使用具有这种复杂度水平的算法而不进行重大操作。这通常适用于所有其他的多项式复杂度 - O(nk)。
O(2n):
不具有可扩展性。您没有希望解决任何规模较大的问题。对于专家来说,它有用于了解需要避免的情况,并寻找在O(nk)中的近似算法。
- Andrew Prock
1
2你能否考虑一下用另一种比喻来解释O(1)?作为一名工程师,我想谈谈由于障碍物引起的射频阻抗问题。 - johnwbyrd
39
大O表示算法相对于其输入大小使用的时间/空间量度。
如果一个算法是O(n),那么时间/空间的增长速度与其输入是同步的。
如果一个算法是O(n2),那么时间/空间的增长速度是其输入平方倍。
以此类推。
- Brownie
6
2这不是关于空间的问题,而是关于复杂性,也就是时间的问题。 - S.Lott
14我一直认为它可以关于时间或空间,但不可能同时涉及两者。 - Rocco
9复杂性绝对可以与空间有关。看看这个链接:http://en.wikipedia.org/wiki/PSPACE - Tom Crockett
4这个答案是这里最“简单”的。之前的回答实际上假设读者已经知道足够的内容来理解它们,但作者不知道这一点。他们认为自己的文字很简单,但实际上并不是这样。用漂亮的格式写很多文本,并且制作对非计算机科学人员而言难以理解的花哨的人工示例,这并不是简单明了的,只是吸引那些大多数是计算机科学人员的stackoverflow用户投票的方式。用简单易懂的英语解释计算机科学术语根本不需要代码和数学。虽然这个答案还不够好,但我给它点了一个赞。 - W.Sun
这个回答犯了一个常见的错误,即假设f=O(g)意味着f和g成比例。 - Paul Hankin
你可以使用大O符号来测量算法的
空间复杂度和时间复杂度。例如,你可以创建一个需要更多空间但能减少时间复杂度的算法,或者你可以创建一个不需要额外空间的算法,比如原地算法。在实践中,人们会选择最适合自己需求的算法,无论是为了提高性能还是为了最小化空间占用等。 - James Oravec网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接