我希望尽可能少使用正式定义和简单的数学语言。
"Big O"符号的通俗易懂解释是什么?(这是一个关于IT技术的问题)
5359
- Arec Barrwin
10
68摘要:算法复杂度的上限。请参考类似问题Big O,如何计算/近似?以获得良好的解释。 - Kosi2801
7其他答案已经很好了,只有一个细节需要理解:O(log n)或类似的表示它取决于输入的“长度”或“大小”,而不是其本身的值。这可能很难理解,但非常重要。例如,在每次迭代中将算法拆分成两部分时就会出现这种情况。 - Harald Schilly
17麻烦您观看麻省理工学院“计算机科学与编程导论”课程第八讲中关于算法复杂性的演讲,链接为http://www.youtube.com/watch?v=ewd7Lf2dr5Q。该讲座用简单易懂的例子对算法复杂性进行了解释,虽然并非全是简单英语,但仍能清晰地阐述相关概念。 - ivanjovanovic
18大 O 表示算法在最大迭代次数下的最坏情况性能估计。它用于评估函数的表现。 - Paul Sweatte
37作为一名自学编程者,解释“大O符号”: “大O符号”是用于描述算法时间复杂度的记号。它表示算法所需执行基本操作的数量,以输入大小的函数形式表示。例如,在最坏情况下,执行n个元素的线性搜索需要O(n)个操作。这个符号非常有用,因为它可以帮助我们比较和选择不同算法之间的效率。然而,它并不考虑实际运行时间,只关注输入大小对执行时间的影响。 - Soner Gönül
显示剩余5条评论
43个回答
13
不确定我是否对这个主题做出了更大贡献,但还是想分享一下:我曾经发现这篇博客文章对于Big O符号的解释和示例非常基础,但也很有帮助:
通过示例,这有助于让我这种龟速思考的人理解最基本的概念,因此我认为这是一个相当不错的10分钟阅读,可以让您朝着正确的方向前进。
- Priidu Neemre
1
@William...人们往往会因为年老而死亡,物种灭绝,行星变得贫瘠等等。 - Priidu Neemre
12
我有更简单的方法来理解时间复杂度。
计算时间复杂度最常用的指标是大O表示法。它会消除所有的常数因素,这样程序运行时间就可以随着N趋近于无穷大而估算。一般来说,你可以这样理解:
statement;
是常数。该语句的运行时间与N无关。
for ( i = 0; i < N; i++ )
statement;
是线性的。循环的运行时间与 N 成正比。当 N 倍增时,运行时间也将倍增。
for ( i = 0; i < N; i++ )
{
for ( j = 0; j < N; j++ )
statement;
}
是二次的。两个循环的运行时间与N的平方成比例。当N加倍时,运行时间增加了N * N。
while ( low <= high )
{
mid = ( low + high ) / 2;
if ( target < list[mid] )
high = mid - 1;
else if ( target > list[mid] )
low = mid + 1;
else break;
}
这是对数时间算法。算法的运行时间与N可以被2整除的次数成比例。这是因为该算法每次迭代将工作区一分为二。
void quicksort ( int list[], int left, int right )
{
int pivot = partition ( list, left, right );
quicksort ( list, left, pivot - 1 );
quicksort ( list, pivot + 1, right );
}
对于运行时间为 N * log ( N ) 的算法,其运行时间由 N 个循环(迭代或递归)组成,这些循环是对数级别的,因此该算法是线性和对数混合的。
一般来说,对于单个维度中的每个项目执行某些操作是线性的,对于两个维度中的每个项目执行某些操作是二次的,而将工作区域分成两半是对数级别的。还有其他的大 O 表示法,如立方,指数和平方根,但它们不太常见。大 O 符号被描述为 O( ) ,其中空格内填写度量。快速排序算法会被描述为 O( N * log ( N ) )。
注意:所有这些都没有考虑最佳、平均和最坏情况。每种情况都有自己的大 O 表示法。另请注意,这是一个非常简单的解释。大 O 是最常见的符号,但它比我展示的更加复杂。还有其他符号,如大 Omega、小 o 和大 Theta。你可能只会在算法分析课程中遇到它们。
- 更多信息:这里
- nitin kumar
12
假设我们正在讨论一个算法A,它应该对一个大小为n的数据集执行某些操作。
那么
通过将A和其他算法进行比较,可以根据它们可能需要执行的操作数(最坏情况)对算法进行排序。
通常,我们的目标是找到或构建一个算法A,使其具有尽可能低的函数
那么
O( <某个包含n的表达式X> )的简单解释为:
恰好有一些函数(把它们想象成X(n)的实现)经常被使用。这些函数是众所周知的且易于比较(例如:1,Log N,N,N^2,N!等)。如果在执行A时不幸的是,完成任务可能需要X(n)次操作。
通过将A和其他算法进行比较,可以根据它们可能需要执行的操作数(最坏情况)对算法进行排序。
通常,我们的目标是找到或构建一个算法A,使其具有尽可能低的函数
X(n)返回值。- Kjartan
12
“Big O”符号的简明解释是什么?
非常快速的说明:
“Big O”中的O代表“Order”(或准确地说是“order of”),因此您可以从字面上理解它被用来对比某些东西的顺序。
请注意行末的顺序,以便更好地理解。如果考虑所有可能性,就会有超过7个符号。
在计算机科学中,用于完成任务的步骤集被称为算法。在术语上,大O符号用于描述算法的性能或复杂度。
此外,大O确定最坏情况或测量上限步骤。您可以参考Big-Ω(Big-Omega)获得最佳情况。 Big-Ω(Big-Omega)符号(文章)|可汗学院 摘要 “大O”描述了算法的性能并对其进行评估。 或正式地说,“大O”对算法进行分类并标准化比较过程。
非常快速的说明:
“Big O”中的O代表“Order”(或准确地说是“order of”),因此您可以从字面上理解它被用来对比某些东西的顺序。
"大O符号"有两个作用:
- 估计计算机完成任务所需的步骤数。
- 通过标准化的符号,方便与其他算法进行比较,以确定其好坏。
有七种最常用的符号:
- O(1),表示计算机只需要
1步就能完成任务,非常优秀,排名第一。 - O(logN),表示计算机完成任务需要
logN步,很不错,排名第二。 - O(N),表示计算机完成任务需要
N步,还可以,排名第三。 - O(NlogN),表示计算机完成任务需要
O(NlogN)步,不太好,排名第四。 - O(N^2),表示计算机完成任务需要
N^2步,很差,排名第五。 - O(2^N),表示计算机完成任务需要
2^N步,非常糟糕,排名第六。 - O(N!),表示计算机完成任务需要
N!步,非常可怕,排名第七。
- O(1),表示计算机只需要
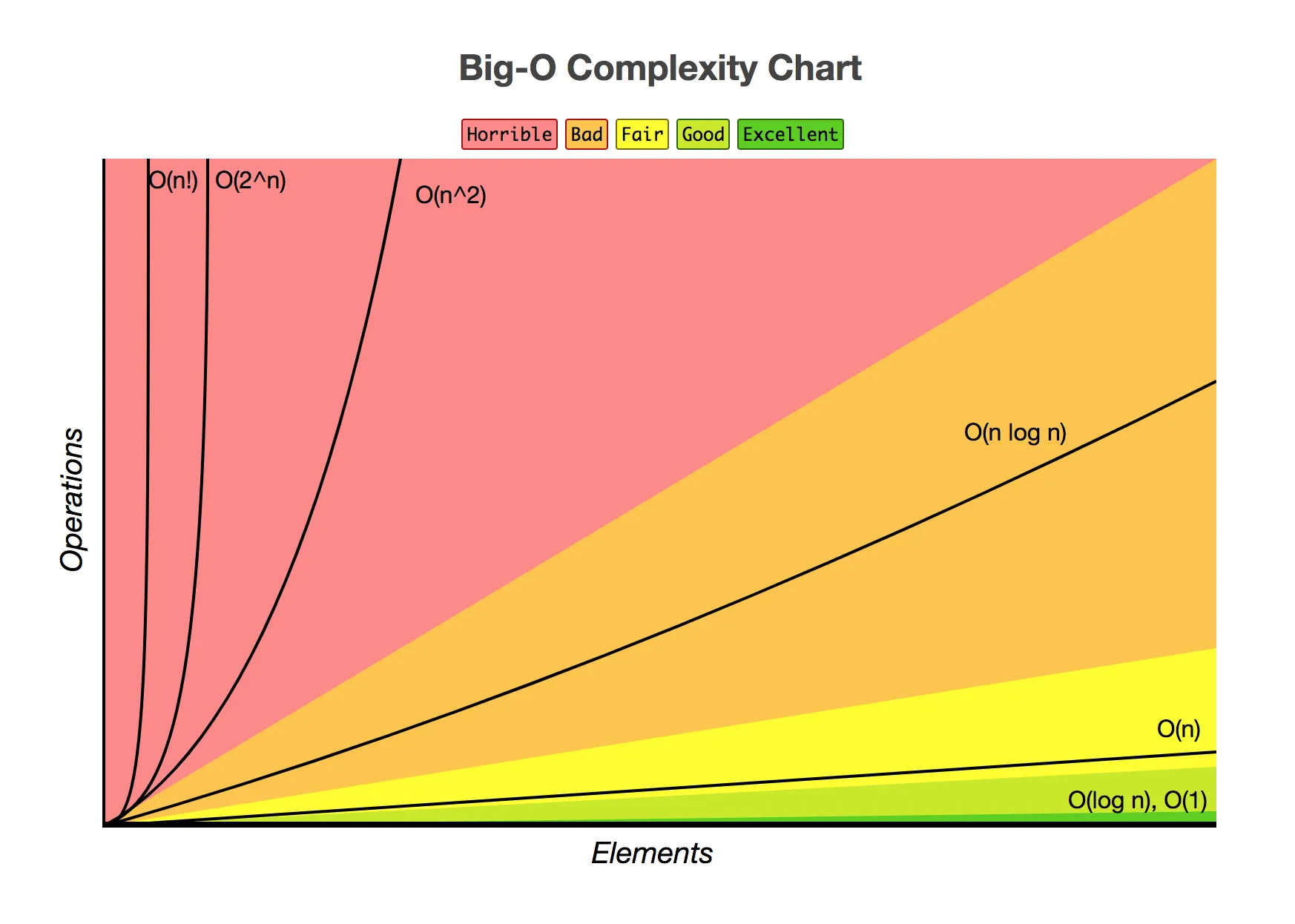
请注意行末的顺序,以便更好地理解。如果考虑所有可能性,就会有超过7个符号。
在计算机科学中,用于完成任务的步骤集被称为算法。在术语上,大O符号用于描述算法的性能或复杂度。
此外,大O确定最坏情况或测量上限步骤。您可以参考Big-Ω(Big-Omega)获得最佳情况。 Big-Ω(Big-Omega)符号(文章)|可汗学院 摘要 “大O”描述了算法的性能并对其进行评估。 或正式地说,“大O”对算法进行分类并标准化比较过程。
- AbstProcDo
11
假设你从亚马逊订购了《哈利·波特:完整八部曲[蓝光]》,同时在网上下载了同样的电影合集。你想测试哪种方法更快。快递需要近一天的时间送到,而下载则提前完成了约30分钟。太好了!所以这是一场激烈的竞赛。
如果我订购了几部蓝光电影,如《魔戒》、《暮光之城》、《黑暗骑士三部曲》等,并同时在线下载所有电影呢?这次,快递仍需要一天才能完成,但在线下载需要三天才能完成。对于在线购物,购买数量(输入)不影响交货时间。输出是恒定的。我们称之为 O(1)。
对于在线下载,下载时间与电影文件大小成正比(输入)。我们称之为 O(n)。
从实验中,我们知道在线购物比在线下载更具可扩展性。理解大O符号非常重要,因为它有助于分析算法的可扩展性和效率。
注:大O符号表示算法的最坏情况。假设以上示例中的 O(1) 和 O(n) 是最坏情况。
参考资料: http://carlcheo.com/compsci
如果我订购了几部蓝光电影,如《魔戒》、《暮光之城》、《黑暗骑士三部曲》等,并同时在线下载所有电影呢?这次,快递仍需要一天才能完成,但在线下载需要三天才能完成。对于在线购物,购买数量(输入)不影响交货时间。输出是恒定的。我们称之为 O(1)。
对于在线下载,下载时间与电影文件大小成正比(输入)。我们称之为 O(n)。
从实验中,我们知道在线购物比在线下载更具可扩展性。理解大O符号非常重要,因为它有助于分析算法的可扩展性和效率。
注:大O符号表示算法的最坏情况。假设以上示例中的 O(1) 和 O(n) 是最坏情况。
参考资料: http://carlcheo.com/compsci
- raaz
11
如果你对无限的概念有一个合适的认识,那么这里有一个非常简短的描述:
大 O 表示法告诉你解决一个无限大问题的成本。
而且
常数因子是可以忽略不计的。
如果你升级到一台可以使你的算法运行速度加倍的计算机,大 O 表示法不会注意到这一点。常数因子的改进在大 O 表示法所涉及的规模中太小,甚至无法被注意到。请注意,这是大 O 表示法设计中故意的一部分。
尽管任何比常数因子“更大”的东西都可以被检测出来。
当你想要进行的计算的大小足够“大”,以至于可以被视为近似无限时,大 O 表示法就是解决你的问题的成本。
如果上面的内容让你感到困惑,那么你的头脑中可能没有一个兼容的直观无限概念,你应该忽略上面的所有内容;我知道将这些想法变得严谨的唯一方法,或者如果它们还没有直观上的用处,就是先教你大O符号或类似的东西。(尽管,一旦你在未来充分理解了大O符号,重新审视这些想法可能是值得的)
大 O 表示法告诉你解决一个无限大问题的成本。
而且
常数因子是可以忽略不计的。
如果你升级到一台可以使你的算法运行速度加倍的计算机,大 O 表示法不会注意到这一点。常数因子的改进在大 O 表示法所涉及的规模中太小,甚至无法被注意到。请注意,这是大 O 表示法设计中故意的一部分。
尽管任何比常数因子“更大”的东西都可以被检测出来。
当你想要进行的计算的大小足够“大”,以至于可以被视为近似无限时,大 O 表示法就是解决你的问题的成本。
如果上面的内容让你感到困惑,那么你的头脑中可能没有一个兼容的直观无限概念,你应该忽略上面的所有内容;我知道将这些想法变得严谨的唯一方法,或者如果它们还没有直观上的用处,就是先教你大O符号或类似的东西。(尽管,一旦你在未来充分理解了大O符号,重新审视这些想法可能是值得的)
- user1084944
10
定义:大O符号是一种表示算法性能如何随着数据输入增加而变化的符号表示法。
当我们谈论算法时,有三个重要的支柱:输入、输出和算法处理。大O是符号表示法,它表示如果数据输入增加,算法处理的性能将以什么速率变化。
我建议您观看这个YouTube视频,其中使用代码示例深入解释大O符号。
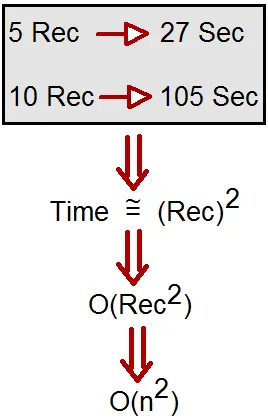
例如,假设一个算法需要处理5条记录,所需的处理时间为27秒。现在如果我们将记录数量增加到10,则算法需要105秒。
简单来说,所需时间是记录数的平方。我们可以用O(n ^ 2)表示这一点。这种符号表示法被称为大O符号。
现在请注意,输入的单位可以是任何东西,比如字节、位、记录数等,性能可以用任何单位来衡量,比如秒、分钟、天等等。因此,它不是精确的单位,而是关系。
例如,看一下下面的函数“Function1”,它接受一个集合并对第一条记录进行处理。现在对于这个函数,无论你放入1000、10000还是100000条记录,性能都是相同的。因此,我们可以用O(1)表示它。
void Function1(List<string> data)
{
string str = data[0];
}
现在看下面的函数"Function2()"。在这种情况下,处理时间会随记录数的增加而增加。我们可以使用O(n)来表示算法性能。
void Function2(List<string> data)
{
foreach(string str in data)
{
if (str == "shiv")
{
return;
}
}
}
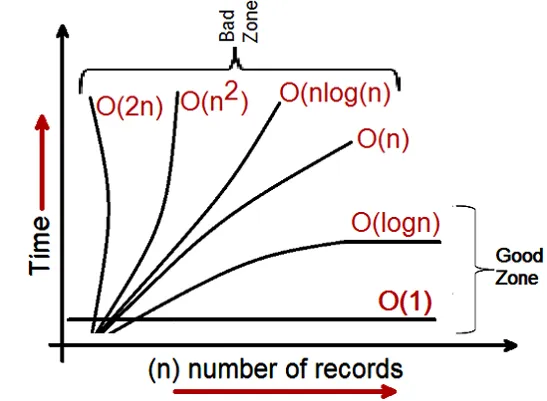
当我们看到一个算法的大O符号时,我们可以将它们分类为三个性能类别:
- 对数和常数类别:任何开发者都希望将他们的算法性能归入此类别。
- 线性:除非是最后一种选择或唯一的选择,否则开发人员不希望将算法归类为此类别。
- 指数:这是我们不希望在我们的算法中看到的地方,需要重新设计算法。
因此,通过查看大O符号,我们可以将算法分为好和坏的区域。
我建议您观看这个10分钟的视频,其中讨论了带有示例代码的大O符号。
- Shivprasad Koirala
9
最简单易懂的解释(用通俗语言)
我们试图了解输入参数的数量如何影响算法的运行时间。如果您的应用程序的运行时间与输入参数的数量成比例,那么它被称为O(n)。
以上陈述是一个好的开始,但不完全准确。
更准确的解释(数学上)
假设
n = 输入参数的数量
T(n) = 表示算法运行时间的实际函数,作为n的函数
c = 一个常数
f(n) = 表示算法运行时间的近似函数,作为n的函数
就大O而言,只要下面的条件成立,近似函数f(n)被认为足够好。
lim T(n) ≤ c×f(n)
n→∞
这个公式的意思是:当n趋近于无穷大时,T(n)小于或等于c乘以f(n)。
在大O符号中,它被写作:
T(n)∈O(n)
这句话可以翻译为“当n趋向于无穷大时,T(n)的增长率不超过O(n)”。根据上述数学定义,如果您说您的算法是Big O of n,则意味着它是n的函数(输入参数的数量)或更快。如果您的算法是Big O of n,则它也自动成为Big O of n平方。
Big O of n意味着我的算法至少以此速度运行。您不能查看您的算法的Big O符号并说它很慢。您只能说它很快。
点击这里观看UC Berkley的Big O视频教程。它实际上是一个简单的概念。如果您听到Shewchuck教授(也称为神级教师)解释它,您会说“哦,就这些内容!”
- developer747
2
视频链接已失效 :( - coler-j
寻找CS 61B讲座19:渐近分析。 - developer747
8
我发现了一篇非常好的关于大O符号的解释,特别是对于不太懂数学的人来说。
https://rob-bell.net/2009/06/a-beginners-guide-to-big-o-notation/
Big O notation is used in Computer Science to describe the performance or complexity of an algorithm. Big O specifically describes the worst-case scenario, and can be used to describe the execution time required or the space used (e.g. in memory or on disk) by an algorithm.
Anyone who's read Programming Pearls or any other Computer Science books and doesn’t have a grounding in Mathematics will have hit a wall when they reached chapters that mention O(N log N) or other seemingly crazy syntax. Hopefully this article will help you gain an understanding of the basics of Big O and Logarithms.
As a programmer first and a mathematician second (or maybe third or fourth) I found the best way to understand Big O thoroughly was to produce some examples in code. So, below are some common orders of growth along with descriptions and examples where possible.
O(1)
O(1) describes an algorithm that will always execute in the same time (or space) regardless of the size of the input data set.
bool IsFirstElementNull(IList<string> elements) { return elements[0] == null; }O(N)
O(N) describes an algorithm whose performance will grow linearly and in direct proportion to the size of the input data set. The example below also demonstrates how Big O favours the worst-case performance scenario; a matching string could be found during any iteration of the for loop and the function would return early, but Big O notation will always assume the upper limit where the algorithm will perform the maximum number of iterations.
bool ContainsValue(IList<string> elements, string value) { foreach (var element in elements) { if (element == value) return true; } return false; }O(N2)
O(N2) represents an algorithm whose performance is directly proportional to the square of the size of the input data set. This is common with algorithms that involve nested iterations over the data set. Deeper nested iterations will result in O(N3), O(N4) etc.
bool ContainsDuplicates(IList<string> elements) { for (var outer = 0; outer < elements.Count; outer++) { for (var inner = 0; inner < elements.Count; inner++) { // Don't compare with self if (outer == inner) continue; if (elements[outer] == elements[inner]) return true; } } return false; }O(2N)
O(2N) denotes an algorithm whose growth doubles with each additon to the input data set. The growth curve of an O(2N) function is exponential - starting off very shallow, then rising meteorically. An example of an O(2N) function is the recursive calculation of Fibonacci numbers:
int Fibonacci(int number) { if (number <= 1) return number; return Fibonacci(number - 2) + Fibonacci(number - 1); }Logarithms
Logarithms are slightly trickier to explain so I'll use a common example:
Binary search is a technique used to search sorted data sets. It works by selecting the middle element of the data set, essentially the median, and compares it against a target value. If the values match it will return success. If the target value is higher than the value of the probe element it will take the upper half of the data set and perform the same operation against it. Likewise, if the target value is lower than the value of the probe element it will perform the operation against the lower half. It will continue to halve the data set with each iteration until the value has been found or until it can no longer split the data set.
This type of algorithm is described as O(log N). The iterative halving of data sets described in the binary search example produces a growth curve that peaks at the beginning and slowly flattens out as the size of the data sets increase e.g. an input data set containing 10 items takes one second to complete, a data set containing 100 items takes two seconds, and a data set containing 1000 items will take three seconds. Doubling the size of the input data set has little effect on its growth as after a single iteration of the algorithm the data set will be halved and therefore on a par with an input data set half the size. This makes algorithms like binary search extremely efficient when dealing with large data sets.
- shanwije
8
前言
算法:用于解决问题的过程/公式。
如何分析算法以及如何比较不同算法之间的差异?
举例:你和朋友都被要求创建一个函数来计算从0到N的数字总和。你想出了f(x),而你的朋友想出了g(x)。两个函数的结果相同,但算法不同。为了客观地比较算法的效率,我们使用大O符号。
大O符号:描述了当输入任意大时,运行时间增长速度与输入增长速度之间的关系。
三个关键点:
- 仅比较运行时间增长速度,而非确切的运行时间(取决于硬件)
- 只考虑与输入(n)相关的运行时间增长
- 当n变得任意大时,着重关注会随着n的增大而增长最快的项(类比无穷大),即渐近分析
空间复杂度:除了时间复杂度外,我们还关心空间复杂度(算法使用的内存/空间大小)。我们检查内存分配的大小,而不是操作时间。
- Ryan Efendy
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接