正如在评论中所指出的,我不认为使用 thrust::copy 直接实现这一目标是可能的。然而,在 thrust 应用程序中,我们可以使用 cudaMemcpyAsync 实现异步复制和复制与计算重叠的目标。
以下是一个具体的示例:
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/system/cuda/experimental/pinned_allocator.h>
#include <thrust/system/cuda/execution_policy.h>
#include <thrust/fill.h>
#include <thrust/sequence.h>
#include <thrust/for_each.h>
#include <iostream>
#define DSIZE (1048576*8)
#define SSIZE (1024*512)
#define LSIZE 1
#define KSIZE 64
#define TV1 1
#define TV2 2
typedef int mytype;
typedef thrust::host_vector<mytype, thrust::cuda::experimental::pinned_allocator<mytype> > pinnedVector;
struct sum_functor
{
mytype *dptr;
sum_functor(mytype* _dptr) : dptr(_dptr) {};
__host__ __device__ void operator()(mytype &data) const
{
mytype result = data;
for (int j = 0; j < LSIZE; j++)
for (int i = 0; i < SSIZE; i++)
result += dptr[i];
data = result;
}
};
int main(){
pinnedVector hi1(DSIZE);
pinnedVector hi2(DSIZE);
pinnedVector ho1(DSIZE);
pinnedVector ho2(DSIZE);
thrust::device_vector<mytype> di1(DSIZE);
thrust::device_vector<mytype> di2(DSIZE);
thrust::device_vector<mytype> do1(DSIZE);
thrust::device_vector<mytype> do2(DSIZE);
thrust::device_vector<mytype> dc1(KSIZE);
thrust::device_vector<mytype> dc2(KSIZE);
thrust::fill(hi1.begin(), hi1.end(), TV1);
thrust::fill(hi2.begin(), hi2.end(), TV2);
thrust::sequence(do1.begin(), do1.end());
thrust::sequence(do2.begin(), do2.end());
cudaStream_t s1, s2;
cudaStreamCreate(&s1); cudaStreamCreate(&s2);
cudaMemcpyAsync(thrust::raw_pointer_cast(di1.data()), thrust::raw_pointer_cast(hi1.data()), di1.size()*sizeof(mytype), cudaMemcpyHostToDevice, s1);
cudaMemcpyAsync(thrust::raw_pointer_cast(di2.data()), thrust::raw_pointer_cast(hi2.data()), di2.size()*sizeof(mytype), cudaMemcpyHostToDevice, s2);
thrust::for_each(thrust::cuda::par.on(s1), do1.begin(), do1.begin()+KSIZE, sum_functor(thrust::raw_pointer_cast(di1.data())));
thrust::for_each(thrust::cuda::par.on(s2), do2.begin(), do2.begin()+KSIZE, sum_functor(thrust::raw_pointer_cast(di2.data())));
cudaMemcpyAsync(thrust::raw_pointer_cast(ho1.data()), thrust::raw_pointer_cast(do1.data()), do1.size()*sizeof(mytype), cudaMemcpyDeviceToHost, s1);
cudaMemcpyAsync(thrust::raw_pointer_cast(ho2.data()), thrust::raw_pointer_cast(do2.data()), do2.size()*sizeof(mytype), cudaMemcpyDeviceToHost, s2);
cudaDeviceSynchronize();
for (int i=0; i < KSIZE; i++){
if (ho1[i] != ((LSIZE*SSIZE*TV1) + i)) { std::cout << "mismatch on stream 1 at " << i << " was: " << ho1[i] << " should be: " << ((DSIZE*TV1)+i) << std::endl; return 1;}
if (ho2[i] != ((LSIZE*SSIZE*TV2) + i)) { std::cout << "mismatch on stream 2 at " << i << " was: " << ho2[i] << " should be: " << ((DSIZE*TV2)+i) << std::endl; return 1;}
}
std::cout << "Success!" << std::endl;
return 0;
}
我的测试用例使用的是RHEL5.5,Quadro5000和cuda 6.5RC。这个示例旨在让thrust创建非常小的内核(仅有一个线程块,只要KSIZE很小,比如32或64),以使从thrust::for_each创建的内核能够并发运行。
当我分析这段代码时,我看到:
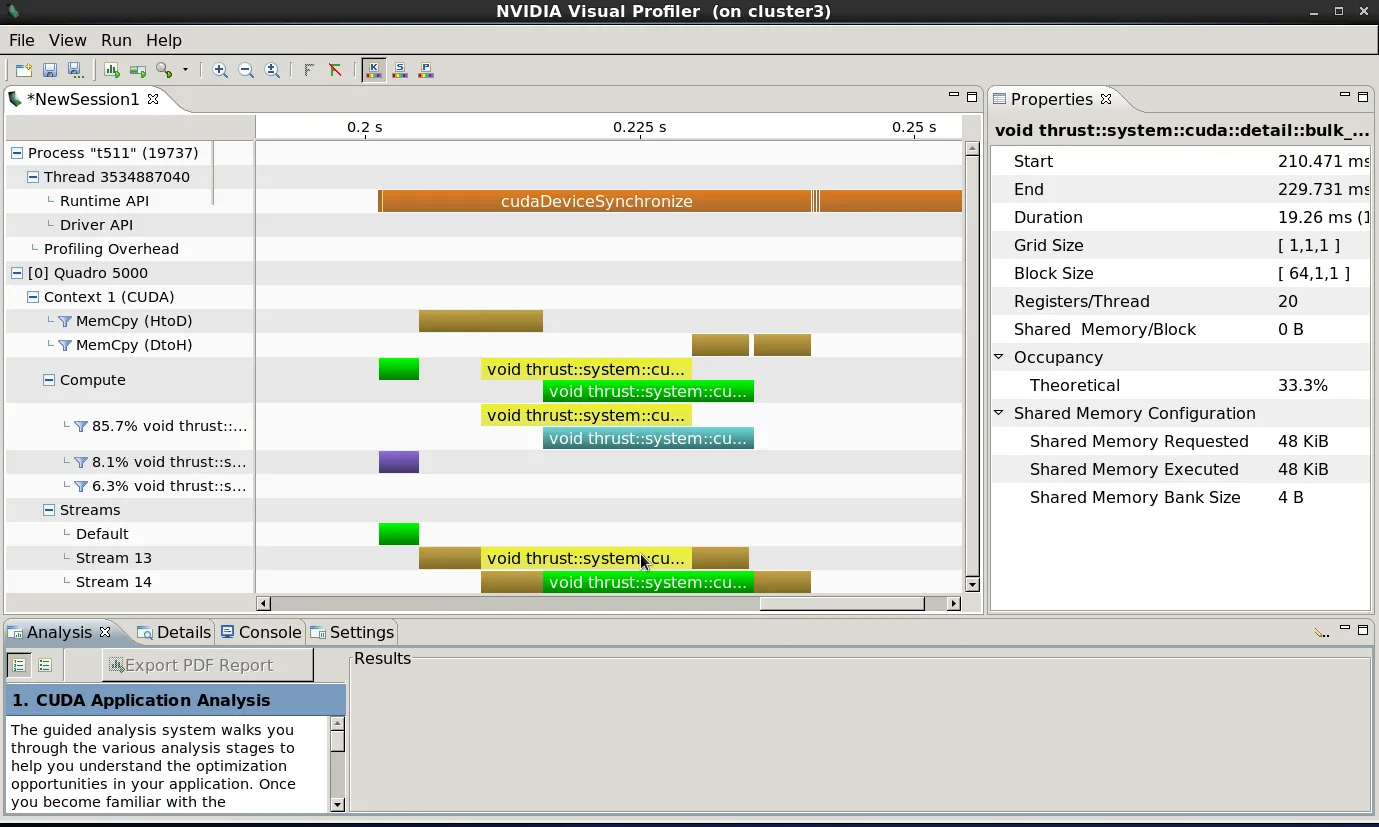
这表明我们正在实现thrust内核之间以及复制操作和thrust内核之间的适当重叠,并且在内核完成时异步进行数据复制。请注意,cudaDeviceSynchronize()操作“填充”时间轴,表明所有异步操作(数据复制、thrust函数)都是异步发出的,控制在任何操作开始之前就返回到主机线程。所有这些都是完全实现主机、GPU和数据复制操作之间并发的预期且正确的行为。
cudaMemcpyAsync来完成。 - Robert CrovellacudaMemcpyAsync。 - Jared Hoberock