在CUDA Thrust的代码中查看内核启动时,似乎它们总是使用默认流。我能否让Thrust使用我选择的流?我是否在API中遗漏了什么?
2个回答
13
在Thrust 1.8发布后,我希望更新talonmies提供的答案,该版本引入了指定CUDA执行流的可能性。
thrust::cuda::par.on(stream)
另请参阅
以下是我在CUDA Thrust API中重构示例:
#include <iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <thrust\device_vector.h>
#include <thrust\execution_policy.h>
#include "Utilities.cuh"
using namespace std;
#define NUM_THREADS 32
#define NUM_BLOCKS 16
#define NUM_STREAMS 3
struct BinaryOp{ __host__ __device__ int operator()(const int& o1,const int& o2) { return o1 * o2; } };
int main()
{
const int N = 6000000;
// --- Host side input data allocation and initialization. Registering host memory as page-locked (required for asynch cudaMemcpyAsync).
int *h_in = new int[N]; for(int i = 0; i < N; i++) h_in[i] = 5;
gpuErrchk(cudaHostRegister(h_in, N * sizeof(int), cudaHostRegisterPortable));
// --- Host side input data allocation and initialization. Registering host memory as page-locked (required for asynch cudaMemcpyAsync).
int *h_out = new int[N]; for(int i = 0; i < N; i++) h_out[i] = 0;
gpuErrchk(cudaHostRegister(h_out, N * sizeof(int), cudaHostRegisterPortable));
// --- Host side check results vector allocation and initialization
int *h_checkResults = new int[N]; for(int i = 0; i < N; i++) h_checkResults[i] = h_in[i] * h_in[i];
// --- Device side input data allocation.
int *d_in = 0; gpuErrchk(cudaMalloc((void **)&d_in, N * sizeof(int)));
// --- Device side output data allocation.
int *d_out = 0; gpuErrchk( cudaMalloc((void **)&d_out, N * sizeof(int)));
int streamSize = N / NUM_STREAMS;
size_t streamMemSize = N * sizeof(int) / NUM_STREAMS;
// --- Set kernel launch configuration
dim3 nThreads = dim3(NUM_THREADS,1,1);
dim3 nBlocks = dim3(NUM_BLOCKS, 1,1);
dim3 subKernelBlock = dim3((int)ceil((float)nBlocks.x / 2));
// --- Create CUDA streams
cudaStream_t streams[NUM_STREAMS];
for(int i = 0; i < NUM_STREAMS; i++)
gpuErrchk(cudaStreamCreate(&streams[i]));
/**************************/
/* BREADTH-FIRST APPROACH */
/**************************/
for(int i = 0; i < NUM_STREAMS; i++) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_in[offset], &h_in[offset], streamMemSize, cudaMemcpyHostToDevice, streams[i]);
}
for(int i = 0; i < NUM_STREAMS; i++)
{
int offset = i * streamSize;
thrust::transform(thrust::cuda::par.on(streams[i]), thrust::device_pointer_cast(&d_in[offset]), thrust::device_pointer_cast(&d_in[offset]) + streamSize/2,
thrust::device_pointer_cast(&d_in[offset]), thrust::device_pointer_cast(&d_out[offset]), BinaryOp());
thrust::transform(thrust::cuda::par.on(streams[i]), thrust::device_pointer_cast(&d_in[offset + streamSize/2]), thrust::device_pointer_cast(&d_in[offset + streamSize/2]) + streamSize/2,
thrust::device_pointer_cast(&d_in[offset + streamSize/2]), thrust::device_pointer_cast(&d_out[offset + streamSize/2]), BinaryOp());
}
for(int i = 0; i < NUM_STREAMS; i++) {
int offset = i * streamSize;
cudaMemcpyAsync(&h_out[offset], &d_out[offset], streamMemSize, cudaMemcpyDeviceToHost, streams[i]);
}
for(int i = 0; i < NUM_STREAMS; i++)
gpuErrchk(cudaStreamSynchronize(streams[i]));
gpuErrchk(cudaDeviceSynchronize());
// --- Release resources
gpuErrchk(cudaHostUnregister(h_in));
gpuErrchk(cudaHostUnregister(h_out));
gpuErrchk(cudaFree(d_in));
gpuErrchk(cudaFree(d_out));
for(int i = 0; i < NUM_STREAMS; i++)
gpuErrchk(cudaStreamDestroy(streams[i]));
cudaDeviceReset();
// --- GPU output check
int sum = 0;
for(int i = 0; i < N; i++) {
//printf("%i %i\n", h_out[i], h_checkResults[i]);
sum += h_checkResults[i] - h_out[i];
}
cout << "Error between CPU and GPU: " << sum << endl;
delete[] h_in;
delete[] h_out;
delete[] h_checkResults;
return 0;
}
Utilities.cu 和 Utilities.cuh 文件是运行这个示例所需的,它们在此Github页面中维护。
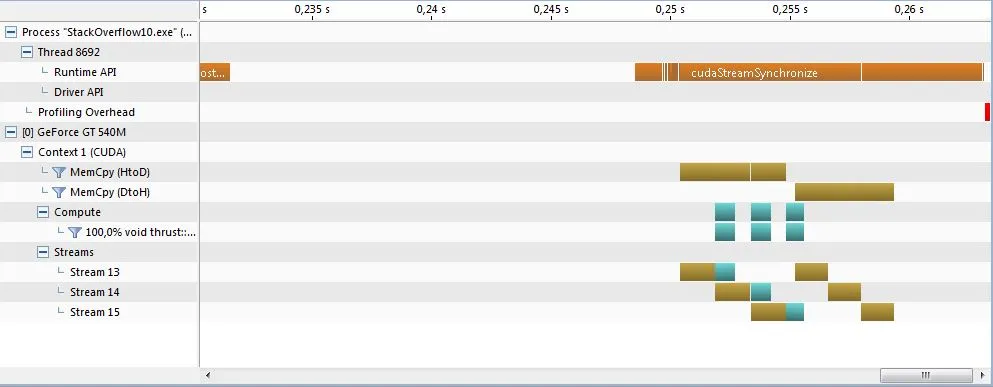
Visual Profiler时间轴显示了CUDA Thrust操作和内存传输的并发性。
- Vitality
3
7
在 CUDA 6.0 发布的版本中,您没有错过任何内容。
原始的 Thrust 标签分发系统有意抽象化了所有底层 CUDA API 调用,为了方便使用和一致性而牺牲了一些性能(请注意,thrust 还有其他后端)。如果您想要这种级别的灵活性,您需要尝试另一个库(例如 CUB)。
自 CUDA 7.0 快照版本以来,通过执行策略和分发特性,可以为 thrust 操作设置所需的流。
- talonmies
2
6使用Thrust的主/开发分支,应该可以开始尝试使用流与Thrust进行实验。实验公告在这里。 - Robert Crovella
5好的,请问需要翻译哪些内容呢? - pqn
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
par意味着什么? - einpoklumthrust::seq或thrust::device一样。 - Vitality