我有一个数据集,第一列是日期,第二列是价格。日期是交易日。
我想要返回一个看起来像这样的表格:
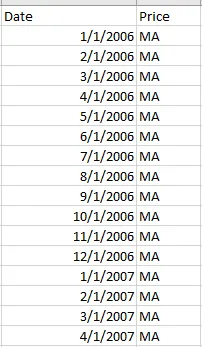
日期是从2006年开始的每个月,价格MA是过去N个月的平均价格。(N = [1,2,3,4,5,6])
例如:如果我想在2006年1月1日使用N = 1 Ma应该是去年12月的平均价格 如果N = 2 Ma应该是去年11月和12月的平均价格
我已经阅读了一些关于从日期时间中提取月份并进行分组的解决方案。 但不知道如何将它们结合起来。
或者你可以简单尝试一下
df.sort_index(ascending=False).rolling(5).mean().sort_index(ascending=True)
针对您的额外问题
index=pd.date_range(start="4th of July 2017",periods=30,freq="D")
df=pd.DataFrame(np.random.randint(0,100,30),index=index)
df['Month']=df.index
df.Month=df.Month.astype(str).str[0:7]
df.groupby('Month')[0].mean()
Out[162]:
Month
2017-07 47.178571
2017-08 56.000000
Name: 0, dtype: float64
编辑3:对于缺失值滚动两个月均值
index=pd.date_range(start="4th of July 2017",periods=300,freq="D")
df=pd.DataFrame(np.random.randint(0,100,300),index=index)
df['Month']=df.index
df.Month=df.Month.astype(str).str[0:7]
df=df.groupby('Month')[0].agg({'sum':'sum','count':'count'})
df['sum'].rolling(2).sum()/df['count'].rolling(2).sum()
Out[200]:
Month
2017-07 NaN
2017-08 43.932203
2017-09 45.295082
2017-10 46.967213
2017-11 46.327869
2017-12 49.081967
#etc
df.sort_index().rolling(5).mean().dropna()。 - 2Oberesample https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.resample.html - BENY将返回指定期数的滚动平均值,使用窗口参数进行计算。例如,window=1将返回原始列表。Window=2将计算2天的平均值,依此类推。
index=pd.date_range(start="4th of July 2017",periods=30,freq="D")
df=pd.DataFrame(np.random.randint(0,100,30),index=index)
print([pd.rolling_mean(df,window=i,freq="D") for i in range(1,5)])
.....
2017-07-04 NaN
2017-07-05 20.5
2017-07-06 64.5
2017-07-07 58.5
2017-07-08 13.0
2017-07-09 4.5
2017-07-10 17.5
2017-07-11 23.5
2017-07-12 40.5
2017-07-13 60.0
2017-07-14 73.0
2017-07-15 90.0
2017-07-16 56.5
2017-07-17 55.0
2017-07-18 57.0
2017-07-19 45.0
2017-07-20 77.0
2017-07-21 46.5
2017-07-22 3.5
2017-07-23 48.5
2017-07-24 71.5
2017-07-25 52.0
2017-07-26 56.5
2017-07-27 47.5
2017-07-28 64.0
2017-07-29 82.0
2017-07-30 68.0
2017-07-31 72.5
2017-08-01 58.5
2017-08-02 67.0
您可以使用df.dropna方法进一步删除NA值,例如:
df.rolling(window=2,freq="D").mean().dropna() #Here you must adjust the window size
因此,应该打印出每个月滚动平均值的完整代码如下:
print([df.rolling(i,freq="m").mean().dropna() for i in range(len(df.rolling(window=1,freq="m").sum()))])
首先,将Date设置为索引:
price_df.set_index('Date', inplace=True)
price_df.index = pd.to_datetime(price_df.index)
然后,从过去的N个月中计算移动平均值:
mv = price_df.rolling(window=i*30, center=False).mean().dropna() 其中 N=i
最后,返回仅包含每个月第一天的子集(如果这是您想要返回的内容):
mv.ix[mv.index.day==1]