假设我有一个类似下面的数据框,我该如何获取两个特定列之间的相关性,然后按“ID”列进行分组?我相信Pandas的'corr'方法可以找到所有列之间的相关性。如果可能,我还想知道如何使用.agg函数找到“groupby”相关性(即np.correlate)。
我有以下内容:
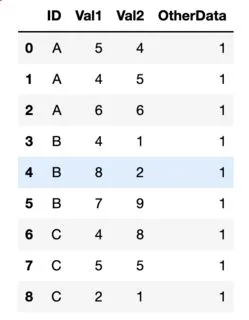
ID Val1 Val2 OtherData OtherData
A 5 4 x x
A 4 5 x x
A 6 6 x x
B 4 1 x x
B 8 2 x x
B 7 9 x x
C 4 8 x x
C 5 5 x x
C 2 1 x x
我需要什么:
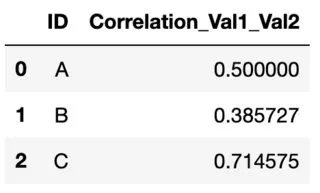
ID Correlation_Val1_Val2
A 0.12
B 0.22
C 0.05
.iloc来搞弄,这正是让我对pandas感到沮丧的原因之一;如果我想为科学数据设置一个大型处理管道,最终感觉就像一切都是用牙膏黏在一起的。 - Cai