我希望在假期期间通过使用Keras获得一些实践经验,所以我想从股票数据的时间序列预测教科书例子入手。因此,我试图根据过去48小时的平均价格变化(与前一时刻相比的百分比)预测未来一小时的平均价格变化。
然而,当与测试集(甚至是训练集)进行验证时,预测序列的振幅差距很大,并且有时会被移动为始终为正或始终为负,即移开了0%变化,我认为这种情况是不正确的。
我提供了以下最小示例来展示这个问题:
df = pandas.DataFrame.from_csv('test-data-01.csv', header=0)
df['pct'] = df.value.pct_change(periods=1)
seq_len=48
vals = df.pct.values[1:] # First pct change is NaN, skip it
sequences = []
for i in range(0, len(vals) - seq_len):
sx = vals[i:i+seq_len].reshape(seq_len, 1)
sy = vals[i+seq_len]
sequences.append((sx, sy))
row = -24
trainSeqs = sequences[:row]
testSeqs = sequences[row:]
trainX = np.array([i[0] for i in trainSeqs])
trainy = np.array([i[1] for i in trainSeqs])
model = Sequential()
model.add(LSTM(25, batch_input_shape=(1, seq_len, 1)))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
model.fit(trainX, trainy, epochs=1, batch_size=1, verbose=1, shuffle=True)
pred = []
for s in trainSeqs:
pred.append(model.predict(s[0].reshape(1, seq_len, 1)))
pred = np.array(pred).flatten()
plot(pred)
plot([i[1] for i in trainSeqs])
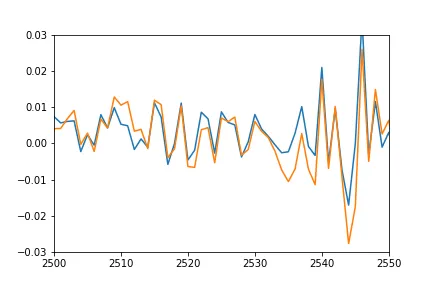
axis([2500, 2550,-0.03, 0.03])
正如你所看到的,我通过选择最后48小时和下一步来创建训练和测试序列,将其组成一个元组,然后每隔1个小时推进一次,并重复该过程。模型是一个非常简单的1个LSTM和1个密集层。
我本来希望预测出的单个点的图与训练序列的图相当吻合(毕竟它们是在同一集合上训练的),并且在测试序列中进行匹配。然而,在训练数据上,我得到了以下结果:
- 橙色:真实数据
- 蓝色:预测数据

有什么想法可能会发生什么事情?我误解了什么吗?
更新:为了更好地展示我所说的平移和压缩,我还绘制了预测值的图形,将其向后偏移以匹配实际数据并乘以比例系数。
plot(pred*12-0.03)
plot([i[1] for i in trainSeqs])
axis([2500, 2550,-0.03, 0.03])
正如你所看到的,预测结果很好地适应了真实数据,只是在某种程度上被压缩和偏移了,我不知道为什么。