所以我尝试了上面的所有方法,但它们仍然不是我想要的(将解释原因)。
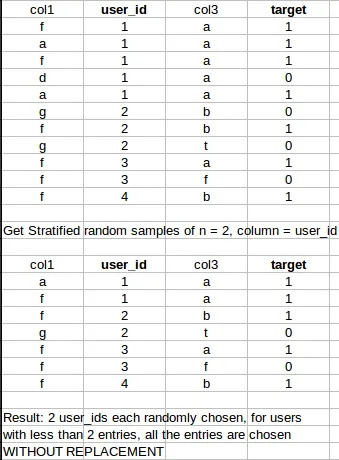
步骤1:是的,我们需要按目标变量进行分组,让我们称其为“target_variable”。因此,代码的第一部分将如下所示:
groupby。
df.groupby('target_variable', group_keys=False)
我设置
group_keys=False,因为我不想将索引继承到输出中。
步骤2:使用
apply从
target_variable中的各个类别中进行采样。
这就是我发现上面的答案并不完全通用的地方。在我的示例中,这是我在
df中作为标签数字的内容:
array(['S1','S2','normal'], dtype=object),
array([799, 2498,3716391])
所以你可以看到我的目标变量是多么不平衡。我需要确保对于每个类别,我都要取
S1标签的数量作为最小样本数。
min(np.unique(df['target_variable'], return_counts=True))
这是
@piRSquared 的答案所缺少的部分。然后你要在班级号码的最小值(这里是
799)和每个班级的数量之间进行选择。这不是一个通用规则,你可以选择其他数字。例如:
max(len(x), min(np.unique(data_use['snd_class'], return_counts=True)[1])
这将给出您最小班级的
max与每个班级的数量相比较的结果。
他们回答中的另一个技术问题是建议在抽样后对输出进行洗牌。也就是说,您不希望所有的
S1样本都在连续的行中,然后是
S2等等。您需要确保您的行是随机堆叠的。这就是
sample(frac=1)的作用。值
1是因为我想在洗牌后返回所有数据。如果您由于任何原因需要更少的数据,请随意提供一个分数,如
0.6,它将返回原始样本的60%,并进行了洗牌。
步骤3:我的最终代码如下:
df.groupby('target_variable', group_keys=False).apply(lambda x: x.sample(min(len(x), min(np.unique(df['target_variable'], return_counts=True)[1]))).sample(frac=1))
我正在选择索引1,即
np.unique(df['target_variable'], return_counts=True)[1],因为这是以
numpy数组形式获取每个类别数量的适当方式。请根据需要进行修改。
 谢谢! :)
谢谢! :)
imblearn的下采样或欠采样技术来解决这个问题:https://imbalanced-learn.org/stable/under_sampling.html - wordsforthewise