我有两个数据框。
我想根据ID列以及df2中的Date列是否在df1的BeginDate和EndDate之间,将df1中的Value列映射到df2上。问题是df1有10,000行,而df2有1,000,000行。
我知道这是可能的。我最关心的是如何快速完成这个任务。
我之前做过类似的事情,只不过df1只有10行,我使用了df1.iterrows来实现。
然而,显然由于df1现在有10,000行,iterrows不再是首选方法。
我考虑过定义一个函数并使用df2.apply,但这将涉及在每次迭代中对df1进行过滤。我以前在这种方法上遇到过效率问题。
可以根据另一列(示例中未显示)将df1分解成较小的数据框。因此,不再有一个大的数据框,而是有10个较小的数据框。我考虑将它们放入一个字典中。这个字典的键可以从df2映射过来,这会有所帮助,但仍然让我面临最初的问题。
我见过使用掩码和df.loc的方法,但还没有找到使用日期条件的方法。
使用pandas完成这个任务并非必需。
df1=
ID Value BeginDate EndDate
1 0.5 1/1/12 1/1/13
1 0.6 1/1/13 1/1/14
2 0.4 1/1/12 1/1/13
3 0.7 1/1/12 1/1/13
df2=
ID Date
1 6/6/12
1 7/5/12
1 10/5/13
2 8/9/12
3 6/6/12
我想根据ID列以及df2中的Date列是否在df1的BeginDate和EndDate之间,将df1中的Value列映射到df2上。问题是df1有10,000行,而df2有1,000,000行。
我知道这是可能的。我最关心的是如何快速完成这个任务。
我之前做过类似的事情,只不过df1只有10行,我使用了df1.iterrows来实现。
df2['Value'] = 1
for index, row in df1.iterrows():
df1['Value'] = np.where(
(row['BeginDate'] <= df2['Date'])
& (df2['Date'] <= row['EndDate']),
row['Value'],
df2['Value'])
然而,显然由于df1现在有10,000行,iterrows不再是首选方法。
我考虑过定义一个函数并使用df2.apply,但这将涉及在每次迭代中对df1进行过滤。我以前在这种方法上遇到过效率问题。
可以根据另一列(示例中未显示)将df1分解成较小的数据框。因此,不再有一个大的数据框,而是有10个较小的数据框。我考虑将它们放入一个字典中。这个字典的键可以从df2映射过来,这会有所帮助,但仍然让我面临最初的问题。
我见过使用掩码和df.loc的方法,但还没有找到使用日期条件的方法。
使用pandas完成这个任务并非必需。
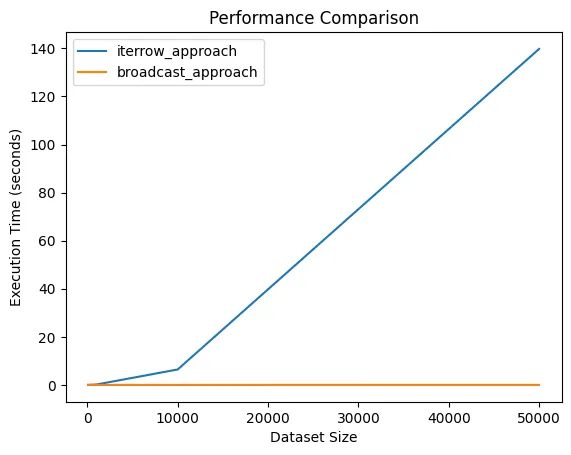
merge函数并加入一些规则,就像这样:merged_df = pd.merge(df1, df2, on="ID")。 - D.Lmerged_df = pd.merge(df1, df2, on="ID")... - D.Lmerge函数。就像这样merged_df = pd.merge(df1, df2, on="ID")... - undefined