使用Pandas内置方法还是pickle.dump更好呢?
标准的pickle方法如下:
pickle.dump(my_dataframe, open('test_pickle.p', 'wb'))
这是Pandas内置方法的样子:
my_dataframe.to_pickle('test_pickle.p')
感谢 @qwwqwwq,我发现 pandas 为数据框提供了内置的 to_pickle 方法。我进行了快速的时间测试:
In [1]: %timeit pickle.dump(df, open('test_pickle.p', 'wb'))
10 loops, best of 3: 91.8 ms per loop
In [2]: %timeit df.to_pickle('testpickle.p')
10 loops, best of 3: 88 ms per loop
所以看起来内置的功能只是略微好一些(对我来说这很有用,因为这意味着重构代码来使用内置的功能可能不值得)-希望这能帮助到某人!
to_pickle有额外的功能吗?只是不用导入pickle的方便吗? - endolithpickle.dump或者df.to_pickle)都差不多,但是使用df.to_pickle创建的文件读取时间要快得多。 使用timeit测试一个大小为53330行x 21列的数据框,使用pickle.dump写入的文件解压需要115毫秒,而使用df.to_pickle写入的文件只需要3毫秒。我不确定这个巨大的加速来自何处,但它是非常显著的。 - Zeph很容易进行基准测试,对吧?
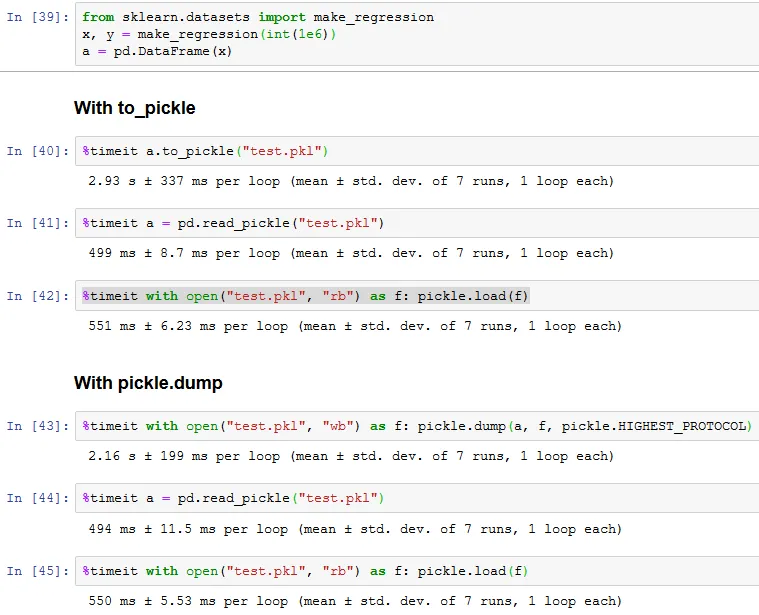
实际上并没有任何区别,我期望Pandas会实现getstate,这样调用pickle.dump(df) 实际上就等同于调用 df.to_pickle()。
如果你在Pandas源代码中搜索例如 __getstate__ ,你会发现它被实现在多个对象中。
panda.DataFrame序列化基准测试的人:FastSerialization。 - Thomas Moreaumy_dataframe.to_pickle('my/weird/path')将无法工作,而pickle.dump(my_dataframe, my_weird_fs.open('/my/weird/path', 'wb'))将正常工作。 - Augustin