我正在尝试使用SparkSQL在数据框之间执行广播哈希连接,如此处所述:https://docs.cloud.databricks.com/docs/latest/databricks_guide/06%20Spark%20SQL%20%26%20DataFrames/05%20BroadcastHashJoin%20-%20scala.html。在该示例中,(小)DataFrame通过saveAsTable进行持久化,然后通过spark SQL进行连接(即通过
sqlContext.sql("...")))。我遇到的问题是我需要使用sparkSQL API来构建我的SQL(我要将约50个表与ID列表左连接,不想手写SQL)。How do I tell spark to use the broadcast hash join via the API? The issue is that if I load the ID list (from the table persisted via `saveAsTable`) into a `DataFrame` to use in the join, it isn't clear to me if Spark can apply the broadcast hash join.
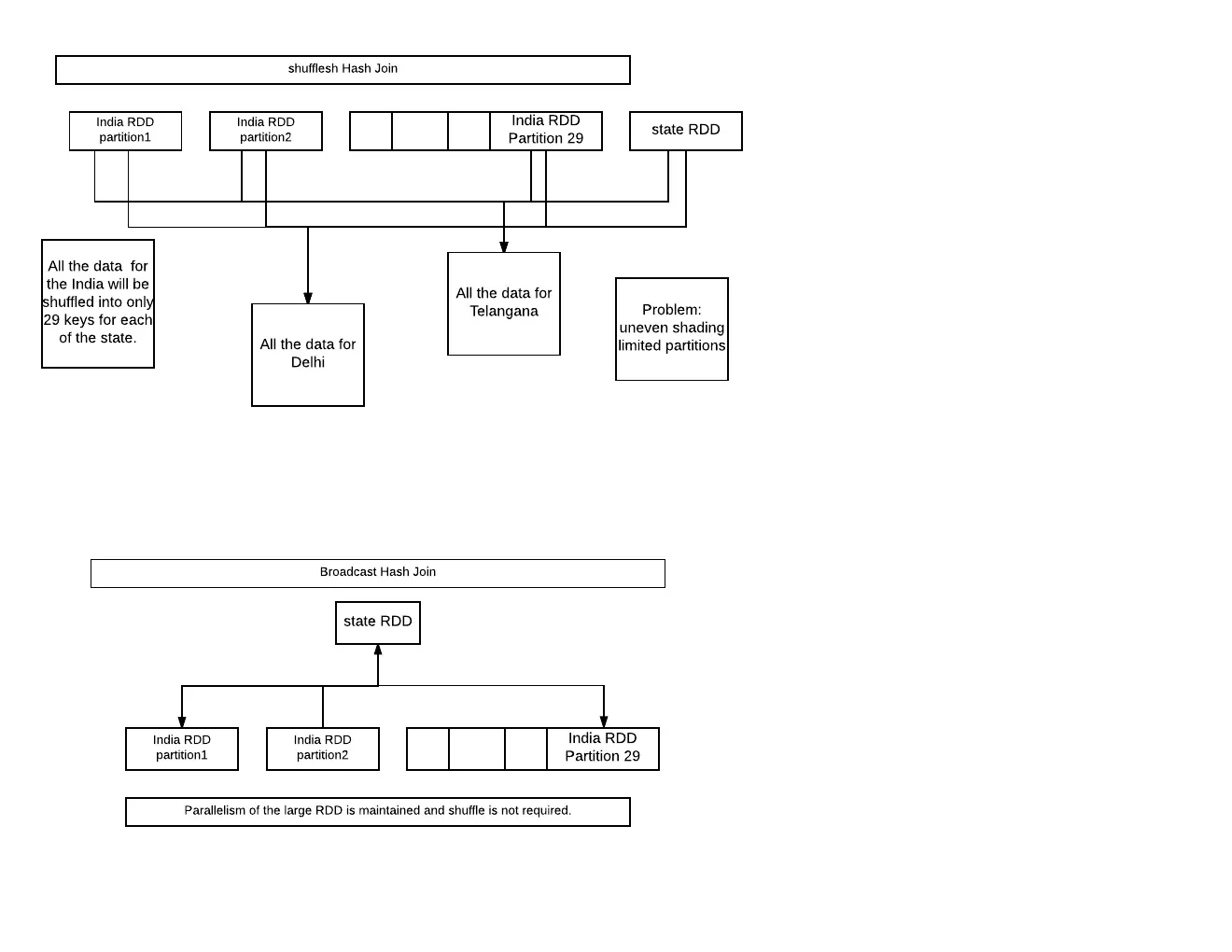
smallDF.join(largeDF)并没有使用广播哈希连接,但largeDF.join(smallDF)是这样的。 - user1759848smallDF.join(LargeDF, "right_outer")可以根据spark.sql.autoBroadcastJoinThreshold自动进行广播,而broadcast函数可以应用于任何位置:broadcast(largeDF).join(smallDF, Seq("foo"))。 - zero323