我正在尝试有效地将两个DataFrame连接起来,其中一个较大,而另一个稍微小一些。
有没有办法避免所有这些洗牌呢?我不能设置autoBroadCastJoinThreshold,因为它只支持整数 - 而我正在尝试广播的表略大于整数字节。
有没有一种方法强制广播忽略此变量?
我正在尝试有效地将两个DataFrame连接起来,其中一个较大,而另一个稍微小一些。
有没有办法避免所有这些洗牌呢?我不能设置autoBroadCastJoinThreshold,因为它只支持整数 - 而我正在尝试广播的表略大于整数字节。
有没有一种方法强制广播忽略此变量?
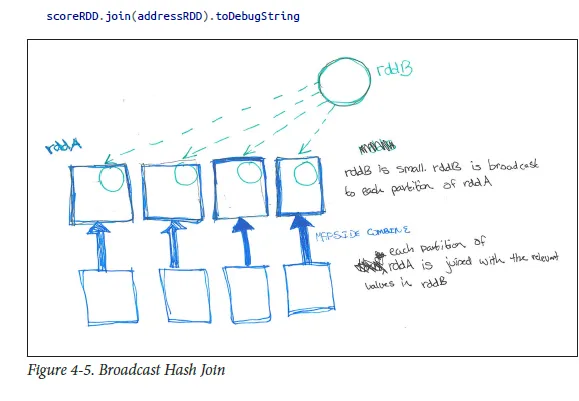
在SparkSQL中,您可以通过调用queryExecution.executedPlan来查看正在执行的连接类型。与核心Spark一样,如果其中一个表比另一个表小得多,则可能需要使用广播哈希连接。您可以通过在连接之前对DataFrame调用方法broadcast来提示Spark SQL应该将给定的DF广播到连接上。
示例:
largedataframe.join(broadcast(smalldataframe), "key")
在DWH术语中,其中largedataframe可能类似于fact
smalldataframe可能类似于dimension
如我最喜欢的书(HPS)所述,请参见下文以了解更好的理解。
请注意:broadcast是从import org.apache.spark.sql.functions.broadcast而不是从SparkContext导入的。
Spark还会自动使用spark.sql.conf.autoBroadcastJoinThreshold来确定是否应该广播表。
def
explain(): Unit
Prints the physical plan to the console for debugging purposes.
有没有一种方法可以强制忽略这个变量进行广播?
sqlContext.sql("SET spark.sql.autoBroadcastJoinThreshold = -1")注意:
关于Hive(而不是Spark)的另一个类似性质的注释:可以使用Hive提示符
MAPJOIN来实现类似的操作,如下所示...
Select /*+ MAPJOIN(b) */ a.key, a.value from a join b on a.key = b.key
hive> set hive.auto.convert.join=true;
hive> set hive.auto.convert.join.noconditionaltask.size=20971520
hive> set hive.auto.convert.join.noconditionaltask=true;
hive> set hive.auto.convert.join.use.nonstaged=true;
hive> set hive.mapjoin.smalltable.filesize = 30000000; // default 25 mb made it as 30mb
进一步阅读:请参考我的关于BHJ、SHJ、SMJ的文章
您可以使用left.join(broadcast(right),...)提示数据框进行广播。
broadcast 这个符号无法解析。 - Chris A.left inner join broadcast(right)这样使用过它,但不确定它是否适用于子查询。 - Sebastian Piuval df = broadcast(spark.table("tableA")).createTempView("tableAView")
spark.sql("SELECT ... FROM tableAView a JOIN tableB b") - Alexander Tronchin-James设置 spark.sql.autoBroadcastJoinThreshold = -1 将完全禁用广播。请参阅Spark SQL、DataFrames 和 Datasets 指南中的其他配置选项。
我发现这段代码适用于Spark 2.11版本2.0.0中的广播连接。
import org.apache.spark.sql.functions.broadcast
val employeesDF = employeesRDD.toDF
val departmentsDF = departmentsRDD.toDF
// materializing the department data
val tmpDepartments = broadcast(departmentsDF.as("departments"))
import context.implicits._
employeesDF.join(broadcast(tmpDepartments),
$"depId" === $"id", // join by employees.depID == departments.id
"inner").show()
以上代码的参考文献为 Henning Kropp博客,使用Spark进行广播连接
使用连接提示将优先于配置autoBroadCastJoinThreshold,因此使用提示将始终忽略该阈值。
此外,在使用连接提示时,自适应查询执行(自Spark 3.x以来)也不会更改提示中给定的策略。
在Spark SQL中,您可以按如下所示应用连接提示:
SELECT /*+ BROADCAST */ a.id, a.value FROM a JOIN b ON a.id = b.id
SELECT /*+ BROADCASTJOIN */ a.id, a.value FROM a JOIN b ON a.id = b.id
SELECT /*+ MAPJOIN */ a.id, a.value FROM a JOIN b ON a.id = b.id