你可以提取数字并形成一个元组,然后对该序列进行排序,并使用其索引对原始数据框进行重新索引。
>>> df.reindex(
df['TC'].str.extractall('(\d+)')
.unstack().astype(int)
.agg(tuple, 1).sort_values()
.index
)
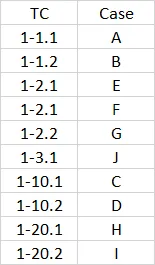
TC Case
0 1-1.1 A
1 1-1.2 B
4 1-2.1 E
5 1-2.1 F
6 1-2.2 G
9 1-3.1 J
2 1-10.1 C
3 1-10.2 D
7 1-20.1 H
8 1-20.2 I
您还可以在sort_values中使用key参数:
>>> df.sort_values('TC',
key=lambda ser:
ser.str.extractall('(\d+)')
.unstack()
.astype(int).agg(tuple, 1)
)
如果一个ID总是由三部分组成,可以使用Series.str.split对非数字字符进行分割,并使用expand=True参数,而不是使用extractall,因此无需使用unstack来处理:
>>> df.sort_values('TC',
key=lambda series:
series.str.split(r'\D+', expand=True)
.astype(int).agg(tuple,1)
)
时间:
>>> %timeit df.reindex(df['TC'].str.extractall('(\d+)').unstack().astype(int).agg(tuple, 1).sort_values().index)
2.95 ms ± 40.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
>>> %timeit df.sort_values('TC', key=lambda ser: ser.str.extractall('(\d+)').unstack().astype(int).agg(tuple, 1))
2.91 ms ± 32.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
>>> %timeit df.sort_values('TC', key=lambda series:series.str.split(r'\D+', expand=True).astype(int).agg(tuple,1))
1.6 ms ± 5.88 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)