选项1
pir1和pir1_5
df.set_index('name').event.str.get_dummies()
event_1 event_2
name
name_1 1 0
name_1 0 1
name_2 1 0
然后您可以对该索引进行求和。
df.set_index('name').event.str.get_dummies().sum(level=0)
event_1 event_2
name
name_1 1 1
name_2 1 0
选项2
pir2
或者你可以使用点积运算
pd.get_dummies(df.name).T.dot(pd.get_dummies(df.event))
event_1 event_2
name_1 1 1
name_2 1 0
选项 3
pir3
高级模式
i, r = pd.factorize(df.name.values)
j, c = pd.factorize(df.event.values)
n, m = r.size, c.size
b = np.bincount(i * m + j, minlength=n * m).reshape(n, m)
pd.DataFrame(b, r, c)
event_1 event_2
name_1 1 1
name_2 1 0
时间控制
res.plot(loglog=True)
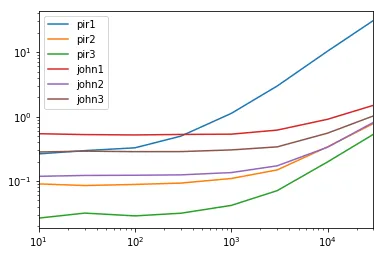
res.div(res.min(1), 0)
pir1 pir2 pir3 john1 john2 john3
10 9.948396 3.399913 1.0 20.478368 4.460466 10.642113
30 9.350524 2.681178 1.0 16.589248 3.847666 9.168907
100 11.414536 3.079463 1.0 18.076040 4.277752 9.949305
300 15.769594 2.940529 1.0 16.745889 3.945470 9.069265
1000 26.869451 2.617564 1.0 12.789570 3.236390 7.279205
3000 42.229542 2.099541 1.0 8.716600 2.429847 4.785814
10000 52.571678 1.716088 1.0 4.597598 1.691989 2.800455
30000 58.644764 1.469827 1.0 2.818744 1.535012 1.929452
功能
pir1 = lambda df: df.set_index('name').event.str.get_dummies().sum(level=0)
pir1_5 = lambda df: pd.get_dummies(df.set_index('name').event).sum(level=0)
pir2 = lambda df: pd.get_dummies(df.name).T.dot(pd.get_dummies(df.event))
def pir3(df):
i, r = pd.factorize(df.name.values)
j, c = pd.factorize(df.event.values)
n, m = r.size, c.size
b = np.bincount(i * m + j, minlength=n * m).reshape(n, m)
return pd.DataFrame(b, r, c)
john1 = lambda df: pd.crosstab(df.name, df.event)
john2 = lambda df: df.groupby(['name', 'event']).size().unstack(fill_value=0)
john3 = lambda df: df.pivot_table(index='name', columns='event', aggfunc='size', fill_value=0)
测试
res = pd.DataFrame(
index=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
columns='pir1 pir2 pir3 john1 john2 john3'.split(),
dtype=float
)
for i in res.index:
d = pd.concat([df] * i, ignore_index=True)
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit(stmt, setp, number=100)
len替换为'size'...df.pivot_table(index='name', columns='event', aggfunc='size', fill_value=0)。我的时间测量做出了这个假设。 - piRSquared