为了学习目的,我一直在尝试构建一个RandomForestClassifier() (RF)模型和一个DecisionTreeClassifier() (DT)模型,以便获得相同的输出。 我已经找到了一些包含答案的问题,例如使两个模型相等所需的参数,但我找不到实际执行此操作的代码,因此我正在尝试构建该代码:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
random_seed = 42
X, y = make_classification(
n_samples=100000,
n_features=5,
random_state=random_seed
)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=random_seed)
DT = DecisionTreeClassifier(criterion='gini', # default
splitter='best', # default
max_depth=None, # default
min_samples_split=3, # default
min_samples_leaf=1, # default
min_weight_fraction_leaf=0.0, # default
max_features=None, # default
random_state=random_seed, # NON-default
max_leaf_nodes=None, # default
min_impurity_decrease=0.0, # default
class_weight=None, # default
ccp_alpha=0.0 # default
)
DT.fit(X_train, y_train)
RF = RandomForestClassifier(n_estimators=1, # NON-default
criterion='gini', # default
max_depth=None, # default
min_samples_split=3, # default
min_samples_leaf=1, # default
min_weight_fraction_leaf=0.0, # default
max_features=None, # NON-default
max_leaf_nodes=None, # default
min_impurity_decrease=0.0, # default
bootstrap=False, # NON-default
oob_score=False, # default
n_jobs=None, # default
random_state=random_seed, # NON-default
verbose=0, # default
warm_start=False, # default
class_weight=None, # default
ccp_alpha=0.0, # default
max_samples=None # default
)
RF.fit(X_train, y_train)
RF_pred = RF.predict(X_test)
RF_proba = RF.predict_proba(X_test)
DT_pred = DT.predict(X_test)
DT_proba = DT.predict_proba(X_test)
# Here we validate that the outputs are actually equal, with their respective percentage of how many rows are NOT equal
print('If DT_pred = RF_pred:',np.array_equal(DT_pred, RF_pred), '; Percentage of not equal:', (DT_pred != RF_pred).sum()/len(DT_pred))
print('If DT_proba = RF_proba:', np.array_equal(DT_proba, RF_proba), '; Percentage of not equal:', (DT_proba != RF_proba).sum()/len(DT_proba))
# A plot that shows where those differences are concentrated
sns.set(style="darkgrid")
mask = (RF_proba[:,1] - DT_proba[:,1]) != 0
only_differences = (RF_proba[:,1] - DT_proba[:,1])[mask]
sns.kdeplot(only_differences, shade=True, color="r")
plt.title('Plot of only differences in probs scores')
plt.show()
输出:
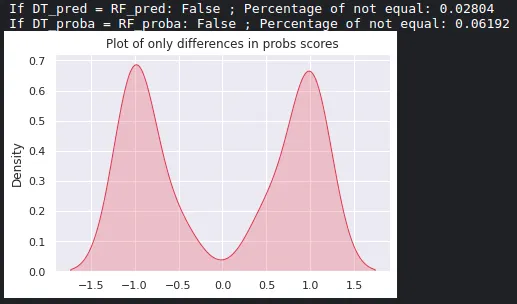
我甚至找到了一个对比XGBoost和DecisionTree的答案,说它们几乎相同,在测试它们的概率输出时,结果却有很大不同。
那么,我做错了什么吗?如何为这两个模型得到相同的概率?有可能在上述代码中让这两个print()语句返回True吗?
RF.estimators_[0].random_state = 42?此外,您能否分享一下您最初观察到的代码?这可以帮助我可视化并学习如何从数据中最终计算概率(实际数学)..这是我的最终目标。 - Chrisdecision_path方法以及底层的tree属性feature和threshold。 - Ben Reiniger