我有一些训练流程,它们很大程度上使用XGBoost而不是scikit-learn,只是因为XGBoost能够干净地处理空值。
然而,我被赋予了向非技术人员介绍机器学习的任务,并认为把单树分类器的概念和XGBoost如何“将其变得更强大”联系起来会很好。具体而言,我想绘制这个单树分类器来展示切点。
指定n_estimators=1是否与使用scikit的DecisionTreeClassifier“大致”等效?
我有一些训练流程,它们很大程度上使用XGBoost而不是scikit-learn,只是因为XGBoost能够干净地处理空值。
然而,我被赋予了向非技术人员介绍机器学习的任务,并认为把单树分类器的概念和XGBoost如何“将其变得更强大”联系起来会很好。具体而言,我想绘制这个单树分类器来展示切点。
指定n_estimators=1是否与使用scikit的DecisionTreeClassifier“大致”等效?
import subprocess
import numpy as np
from xgboost import XGBClassifier, plot_tree
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
RANDOM_STATE = 100
params = {
'max_depth': 5,
'min_samples_leaf': 5,
'random_state': RANDOM_STATE
}
X, y = make_classification(
n_samples=1000000,
n_features=5,
random_state=RANDOM_STATE
)
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=RANDOM_STATE)
# __init__(self, max_depth=3, learning_rate=0.1,
# n_estimators=100, silent=True,
# objective='binary:logistic', booster='gbtree',
# n_jobs=1, nthread=None, gamma=0,
# min_child_weight=1, max_delta_step=0,
# subsample=1, colsample_bytree=1, colsample_bylevel=1,
# reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
# base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
xgb_model = XGBClassifier(
n_estimators=1,
max_depth=3,
min_samples_leaf=5,
random_state=RANDOM_STATE
)
# __init__(self, criterion='gini',
# splitter='best', max_depth=None,
# min_samples_split=2, min_samples_leaf=1,
# min_weight_fraction_leaf=0.0, max_features=None,
# random_state=None, max_leaf_nodes=None,
# min_impurity_decrease=0.0, min_impurity_split=None,
# class_weight=None, presort=False)
sk_model = DecisionTreeClassifier(
max_depth=3,
min_samples_leaf=5,
random_state=RANDOM_STATE
)
xgb_model.fit(Xtrain, ytrain)
xgb_pred = xgb_model.predict(Xtest)
sk_model.fit(Xtrain, ytrain)
sk_pred = sk_model.predict(Xtest)
print(metrics.classification_report(ytest, xgb_pred))
print(metrics.classification_report(ytest, sk_pred))
plot_tree(xgb_model, rankdir='LR'); plt.show()
export_graphviz(sk_model, 'sk_model.dot'); subprocess.call('dot -Tpng sk_model.dot -o sk_model.png'.split())
一些性能指标(我知道,我没有完全校准分类器)...
>>> print(metrics.classification_report(ytest, xgb_pred))
precision recall f1-score support
0 0.86 0.82 0.84 125036
1 0.83 0.87 0.85 124964
micro avg 0.85 0.85 0.85 250000
macro avg 0.85 0.85 0.85 250000
weighted avg 0.85 0.85 0.85 250000
>>> print(metrics.classification_report(ytest, sk_pred))
precision recall f1-score support
0 0.86 0.82 0.84 125036
1 0.83 0.87 0.85 124964
micro avg 0.85 0.85 0.85 250000
macro avg 0.85 0.85 0.85 250000
weighted avg 0.85 0.85 0.85 250000
还有一些图片:

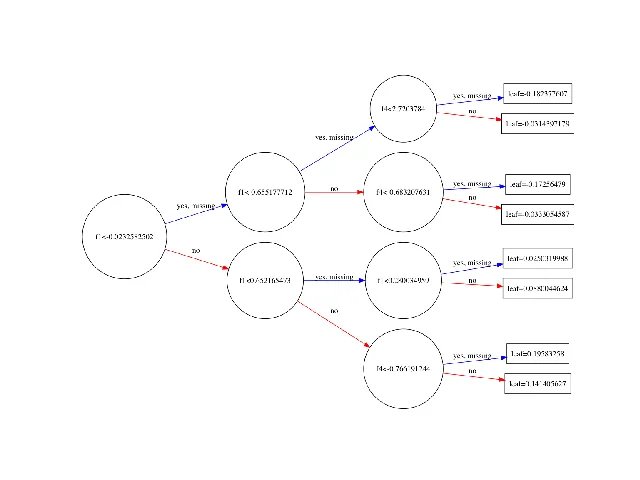
所以,在没有任何调查错误或过度概括的情况下,具有一个估计器的XGBClassifier (我想,回归器也是如此)与具有相同共享参数的scikit-learn DecisionTreeClassifier 看起来非常相似。
np.array_equal(xgb_pred, sk_pred),它会返回 True,因为阈值为0.5用于分类正类和负类。然而,如果你执行 np.array_equal(xgb_proba, sk_proba),其中 sk_proba = sk_model.predict_proba(Xtest) 和 xgb_proba = xgb_model.predict_proba(Xtest),它会返回 False。因此,你关于 XGBClassifier 的例子并不等同于 DecisionTreeClassifier(它们的分数有显著差异),例如第一行的概率为 0.9896 对于 xgb 和 0.643 对于 DecisionTree。 - Chris将XGBoost的n_estimators设置为1会使算法生成一棵单独的树(基本上没有提升),这与sklearn-DecisionTreeClassifier的单树算法类似。
但是,两者可以调整的超参数和树生成过程是不同的。虽然sklearn DecisionTreeClassifier允许您调整比xgboost更多的超参数,但在超参数调整后,xgboost将产生更好的准确性。由xgboost生成的单棵树比由sklearn DecisionTreeClassifier生成的单棵树更好。
xgboost的另一个优点是它可以自己处理缺失值。在DecisionTreeClassifier中,我们必须明确定义一个函数来处理缺失值,这可能会导致不同的结果。
因此,选择n_estimators=1的xgboost而不是sklearn DecisionTreeClassifier!
reg_lambda的确切含义 - 也许这也应该设置为0(请参见此讨论)?现在,我强烈建议您将更新内容作为对您最初问题的答案发布... :) - desertnaut