我有一个Pandas DataFrame,它看起来类似于这个样子,但有10,000行和500列。
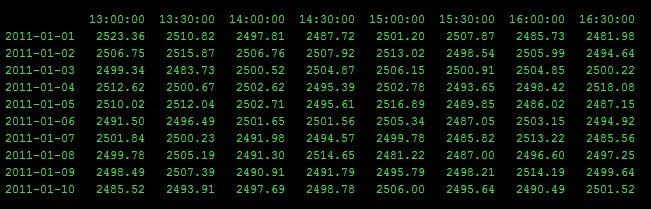
对于每一行,我想找到在3天前下午3点和今天下午1:30之间的最小值。
是否有一些本地numpy方法可以快速完成这个任务? 我的目标是通过类似于“从3天前15:00到0天前(也就是今天)13:30的最小值是多少?”这样的方式获取每行的最小值。
对于这个特定示例,最后两行的答案将是:
2011-01-09 2481.22
2011-01-10 2481.22
我的目前方法是这样的:
1. Get the earliest row (only the values after the start time)
2. Get the middle rows
3. Get the last row (only the values before the end time)
4. Concat (1), (2), and (3)
5. Get the minimum of (4)
但在大型DataFrame上,这需要很长时间。
以下代码将生成一个类似的DF:
import numpy
import pandas
import datetime
numpy.random.seed(0)
random_numbers = (numpy.random.rand(10, 8)*100 + 2000)
columns = [datetime.time(13,0) , datetime.time(13,30), datetime.time(14,0), datetime.time(14,30) , datetime.time(15,0), datetime.time(15,30) ,datetime.time(16,0), datetime.time(16,30)]
index = pandas.date_range('2011/1/1', '2011/1/10')
df = pandas.DataFrame(data = random_numbers, columns=columns, index = index).astype(int)
print df
这是数据框的 JSON 版本:
'{"13:00:00":{"1293840000000":2085,"1293926400000":2062,"1294012800000":2035,"1294099200000":2086,"1294185600000":2006,"1294272000000":2097,"1294358400000":2078,"1294444800000":2055,"1294531200000":2023,"1294617600000":2024},"13:30:00":{"1293840000000":2045,"1293926400000":2039,"1294012800000":2035,"1294099200000":2045,"1294185600000":2025,"1294272000000":2099,"1294358400000":2028,"1294444800000":2028,"1294531200000":2034,"1294617600000":2010},"14:00:00":{"1293840000000":2095,"1293926400000":2006,"1294012800000":2001,"1294099200000":2032,"1294185600000":2022,"1294272000000":2040,"1294358400000":2024,"1294444800000":2070,"1294531200000":2081,"1294617600000":2095},"14:30:00":{"1293840000000":2057,"1293926400000":2042,"1294012800000":2018,"1294099200000":2023,"1294185600000":2025,"1294272000000":2016,"1294358400000":2066,"1294444800000":2041,"1294531200000":2098,"1294617600000":2023},"15:00:00":{"1293840000000":2082,"1293926400000":2025,"1294012800000":2040,"1294099200000":2061,"1294185600000":2013,"1294272000000":2063,"1294358400000":2024,"1294444800000":2036,"1294531200000":2096,"1294617600000":2068},"15:30:00":{"1293840000000":2090,"1293926400000":2084,"1294012800000":2092,"1294099200000":2003,"1294185600000":2001,"1294272000000":2049,"1294358400000":2066,"1294444800000":2082,"1294531200000":2090,"1294617600000":2005},"16:00:00":{"1293840000000":2081,"1293926400000":2003,"1294012800000":2009,"1294099200000":2001,"1294185600000":2011,"1294272000000":2098,"1294358400000":2051,"1294444800000":2092,"1294531200000":2029,"1294617600000":2073},"16:30:00":{"1293840000000":2015,"1293926400000":2095,"1294012800000":2094,"1294099200000":2042,"1294185600000":2061,"1294272000000":2006,"1294358400000":2042,"1294444800000":2004,"1294531200000":2099,"1294617600000":2088}}'
df.head().to_json()的结果,以便我能够尽快在我的会话中获得类似的数据。 - chthonicdaemon