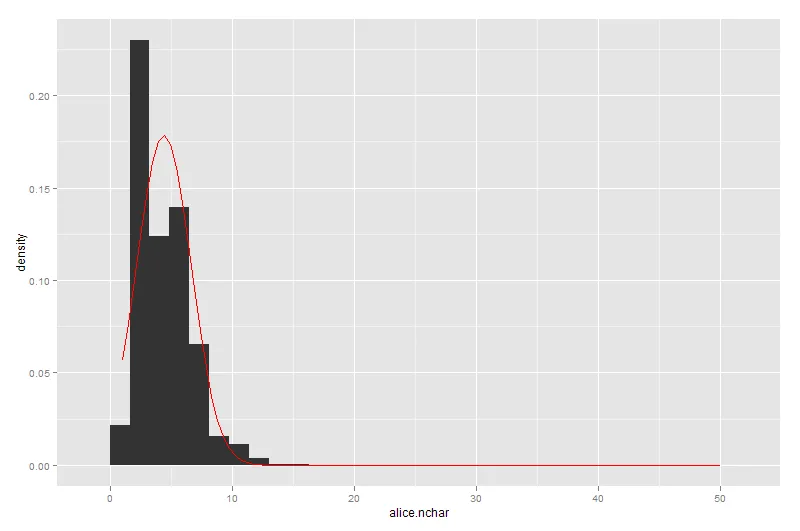
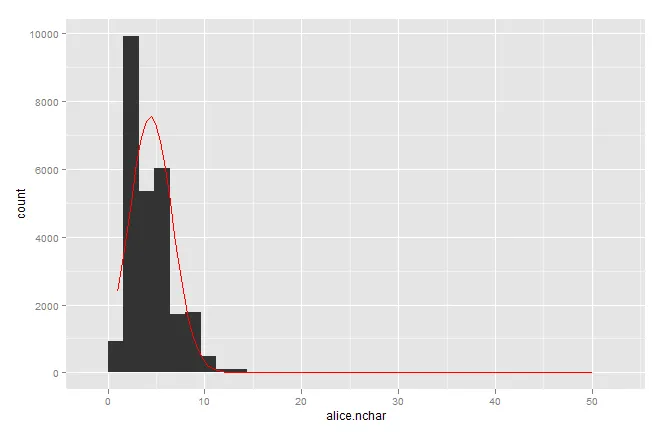
如何使用ggplot对直方图进行任意参数分布的叠加?
我根据Quick-R样例尝试了一下,但我不理解其中的缩放因子从何而来。这种方法合理吗?如何修改以便在ggplot中使用?
以下是使用此方法叠加正态分布和对数正态分布的示例:
## Get a log-normalish data set: the number of characters per word in "Alice in Wonderland"
alice.raw <- readLines(con = "http://www.gutenberg.org/cache/epub/11/pg11.txt",
n = -1L, ok = TRUE, warn = TRUE,
encoding = "UTF-8")
alice.long <- paste(alice.raw, collapse=" ")
alice.long.noboilerplate <- strsplit(alice.long, split="\\*\\*\\*")[[1]][3]
alice.words <- strsplit(alice.long.noboilerplate, "[[:space:]]+")[[1]]
alice.nchar <- nchar(alice.words)
alice.nchar <- alice.nchar[alice.nchar > 0]
# Now we want to plot both the histogram and then log-normal probability dist
require(MASS)
h <- hist(alice.nchar, breaks=1:50, xlab="Characters in word", main="Count")
xfit <- seq(1, 50, 0.1)
# Plot a normal curve
yfit<-dnorm(xfit,mean=mean(alice.nchar),sd=sd(alice.nchar))
yfit <- yfit * diff(h$mids[1:2]) * length(alice.nchar)
lines(xfit, yfit, col="blue", lwd=2)
# Now plot a log-normal curve
params <- fitdistr(alice.nchar, densfun="lognormal")
yfit <- dlnorm(xfit, meanlog=params$estimate[1], sdlog=params$estimate[1])
yfit <- yfit * diff(h$mids[1:2]) * length(alice.nchar)
lines(xfit, yfit, col="red", lwd=2)
这将产生以下图表:
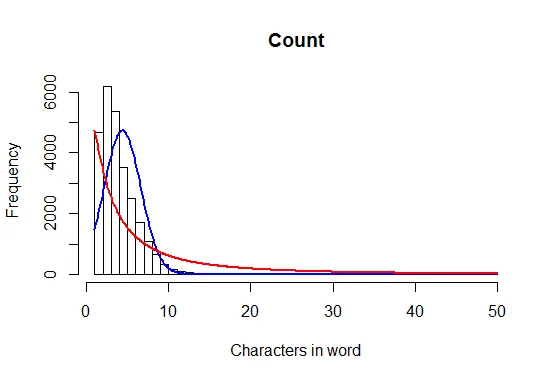 为了澄清,我希望y轴上有计数,而不是密度估计。
为了澄清,我希望y轴上有计数,而不是密度估计。